

ماژول 4: بررسی معماری موتور رندرینگ مرورگر
در این سند به بررسی معماری مدرن موتورهای رندرینگ میپردازیم و پیادهسازی بخشهای مختلف آن را با تمرکز بر موتور Gecko تحلیل میکنیم
نویسنده: رضا احمدی
تاریخ انتشار: 10 مرداد 1404
فهرست
معرفی موتور Gecko
Gecko موتور رندرینگ وب موزیلا است که متشکل از پارز و رندر HTML، شبکه، جاوااسکریپت، IPC، DOM و غیره میباشد. Gecko با زبانهای C++ و جاوااسکریپت توسعه داده شده است و از سال 2016 به بعد، زبان Rust نیز به آن اضافه شد. این موتور نرمافزاری آزاد و اوپنسورس است. موزیلا بهصورت رسمی از استفاده Gecko در سیستمعاملهای Android، Linux، macOS و Windows پشتیبانی میکند.
توسعهی موتور Gecko در سال 1997 توسط شرکت Netscape آغاز شد. پس از راهاندازی پروژه Mozilla در اوایل سال 1998، کد موتور Gecko بهصورت متنباز منتشر شد. این موتور در ابتدا با نام Raptor معرفی شد و سپس نام آن به NGLayout (مخفف next generation layout) تغییر یافت. شرکت Netscape بعدها NGLayout را با نام Gecko بازنامگذاری کرد. در اکتبر 1998، Netscape اعلام کرد که مرورگر بعدی این شرکت از موتور Gecko استفاده خواهد کرد. در نهایت، Netscape 6 در نوامبر سال 2000 منتشر شد و نخستین نسخهای بود که از موتور Gecko بهره میبرد. بنیاد موزیلا در سال 2003 به توسعهدهنده اصلی Gecko تبدیل شد.
در اکتبر 2016، موزیلا پروژهای به نام Quantum را معرفی کرد. این پروژه شامل بهبودهای متعددی در Gecko بود که از پروژهی آزمایشی Servo گرفته شده بودند. مرورگر Firefox 57، که با نام Firefox Quantum نیز شناخته میشود، اولین نسخهای بود که شامل ویژگیهای اصلی پروژههای Quantum/Servo بود و در نوامبر 2017 عرضه شد. این ویژگیها شامل افزایش عملکرد در بخشهای CSS و رندر GPU میشد. در سپتامبر 2018، موزیلا پروژهای به نام GeckoView را معرفی کرد. این پروژه مربوط به نسل بعدی محصولات موبایل موزیلا است که امکان استفادهی مجدد از Gecko در اندروید را فراهم میکند. در همان زمان Firefox Focus 7.0 عرضه شد و اولین نسخهای بود که GeckoView در آن بهکار گرفته شد.
خطلوله رندرینگ
بهطور کلی مسئولیت موتور رندرینگ نمایش محتوای درخواستی روی صفحه مرورگر است. بهطور پیشفرض، موتور رندرینگ میتواند اسناد HTML، XML و همچنین تصاویر را نمایش دهد. این موتور از طریق پلاگینها یا اکستنشنها، میتواند دیگر انواع داده (مانند اسناد PDF) را نیز نمایش دهد. با این حال، در این سند تمرکز ما روی کاربرد اصلی موتور رندرینگ (یعنی نمایش HTML و تصاویری که با CSS فرمتدهی شدهاند) است. جدول زیر موتورهای رندرینگ مرورگرهای مختلف را نشان میدهد:
| موتور رندرینگ | مرورگر |
|---|---|
| Trident | IE |
| Blink | Edge |
| Webkit | Safari |
| Blink | Chrome |
| Gecko | Firefox |
جدول 1: موتور رندرینگ مرورگرها
روند کلی
در ابتدا، موتور رندرینگ شروع به دریافت محتوای سند درخواستی از لایه شبکه میکند. این کار معمولا به صورت Chuckهایی با اندازه 8-کیلوبایت انجام میشود. سپس روند کلی موتور رندرینگ به صورت زیر انجام میشود.
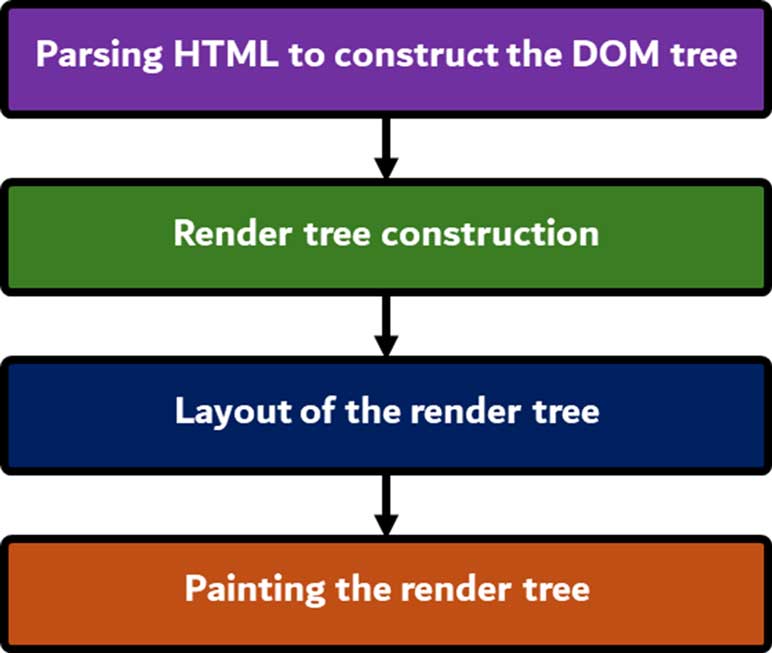
موتور رندرینگ شروع به پارز کردن سند HTML میکند و المانها را در درختی به نام Content Tree به ‘گره (Node)های DOM تبدیل میکند. سپس موتور، دادههای استایل را از فایلهای CSS و المانهای Style در HTML، پارز میکند. اطلاعات مربوط به استایل، همراه با دستورالعملهای بصری در HTML، برای ساخت درخت دیگری به کار میرود که به آن درخت رندر یا Render Tree گفته میشود. درخت رندر شامل مستطیلهایی با ویژگیهای بصری مانند رنگ و ابعاد است. این مستطیلها به ترتیبی سازماندهی شدهاند که بهدرستی روی صفحه نمایش داده شوند. پس از ساخت درخت رندر، این درخت وارد فرآیند چیدمان (Layout) میشود. بدین معنا که به هر گره، مختصات دقیق داده میشود که در کدام قسمت از صفحه باید ظاهر شود. مرحله بعدی رسم (Painting) است که در آن، درخت رندر پیمایش میشود و توسط لایهی بکاندِ UI، گرههای آن رسم میشود. برای ارائه تجربه کاربری بهتر، موتور رندرینگ تلاش میکند تا محتوا را در سریعترین زمان ممکن روی صفحه نمایش دهد. یعنی منتظر نمیماند تا کل HTML پارز شود، بلکه بخشی از محتوا پارز شده و نمایش داده میشود و همزمان مابقی محتوا همچنان از شبکه دریافت میشود و پردازش ادامه دارد.
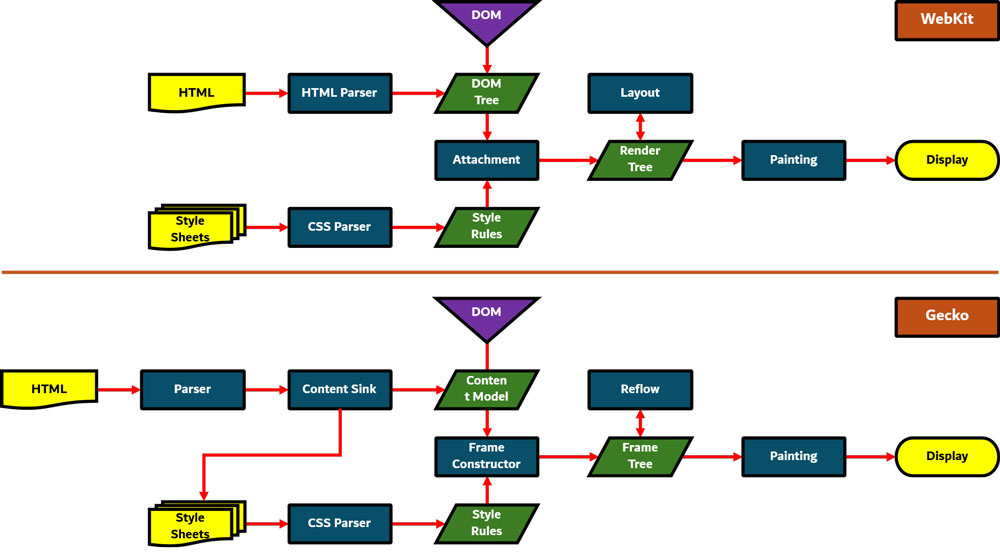
در Gecko به درختی که شامل عناصر صفحه با شکل و ظاهر مشخص است، Frame Tree گفته میشود. هر عنصر در این درخت، یک فریم است. در مقابل، WebKit از اصطلاح Render Tree استفاده میکند که متشکل از آبجکتهای رندر است. WebKit فرآیند تعیین موقعیت عناصر را چیدمان (Layout) مینامد، در حالی که Gecko این فرآیند را Reflow میخواند. WebKit اصطلاح Attachment را برای اتصال گرههای DOM با اطلاعات ظاهری، جهت ایجاد درخت رندر بهکار میبرد. Gecko یک لایه اضافی به نام Content Sink، بین HTML و درخت DOM دارد که در واقع مانند کارخانهای برای ساختن عناصر DOM است. در ادامه به بررسی هر بخش از این فرآیند خواهیم پرداخت.
فرآیند پارز کردن
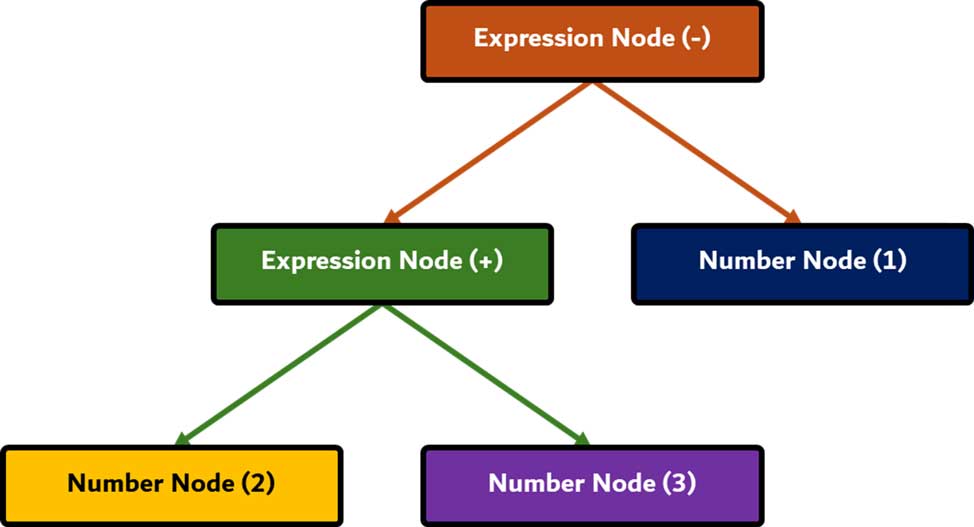
پارز کردن یک سند، به معنای ترجمه آن به ساختاری است که کد بتواند از آن استفاده کند. نتیجه آن معمولا یک درخت از گرههاست که ساختار سند را نمایش میدهد. به این درخت، Parse Tree یا Syntax Tree گفته میشود. برای مثال، پارز کردن عبارت 2 + 3 – 1 ممکن است چنین درختی را بازگرداند:
گرامر
پارز کردن بر پایه قواعد نحویای انجام میشود که سند از آنها پیروی میکند؛ یعنی زبانی که سند با آن نوشته شده است. هر فرمتی که بتوان آن را پارز کرد، باید دارای گرامر مشخصی باشد که از واژگان و قواعد نحوی تشکیل شده است. به این گرامر، گرامر مستقل از متن (Context-Free Grammer) گفته میشود. زبانهای انسانی چنین گرامری ندارند و بنابراین نمیتوان آنها را با تکنیکهای معمول پارز کردن تحلیل کرد.
ترکیب پارزر و لکسر (Lexer)
بهطور کلی، پارز کردن را میتوان به دو زیرفرایند تقسیم کرد: تحلیل واژگانی (Lexical Analysis) و تحلیل نحوی (Syntax Analysis). تحلیل واژگانی فرایند شکستن ورودی به توکنها است، که معادل واژگان زبان هستند. در زبان انسان، این مجموعه شامل تمام کلماتی است که در واژگان آن زبان وجود دارند. تحلیل نحوی به معنای اعمال قواعد نحوی زبان است.
پارزرها معمولا این کار را بین دو مؤلفه تقسیم میکنند: لکسر (گاهی tokenizer نامیده میشود) که وظیفهاش شکستن ورودی به توکنهای معتبر است و پارزر که وظیفهاش ساختن درخت پارز با تحلیل ساختار سند طبق قواعد نحوی زبان است.
انواع پارزر
پارزرها به دو دسته پارزرهای بالا به پایین (Top-down) و پایین به بالا (Bottom-up) تقسیم میشوند. بهطور کلی پارزرهای بالا به پایین، ساختار کلی و سطح بالای سینتکس را بررسی میکنند، اما پارزرهای پایین به بالا، بررسی را از ورودی شروع میکنند. مثال 2 + 3 – 1 را در نظر بگیرید:
- پارزر بالا به پایین : ابتدا 2 + 3 را به عنوان یک عبارت (Expression) شناسایی میکند. سپس 2 + 3 – 1 را نیز به عنوان یک عبارت شناسایی میکند. در واقع فرایند شناسایی عبارت، به مرور با منطبق شدن ورودی با دیگر قوانین تکمیل میشود.
- پارزر پایین به بالا : ورودی را اسکن میکند تا زمانی که یک قانون منطبق پیدا کند. این نوع پارزر Shift-Reduce Parser نام دارد، زیرا ورودی را به سمت راست شیفت داده و میخواند (برای مثال ابتدا 2 خوانده میشود، سپس +، سپس 3 و الی آخر) و بهتدریج قواعد نحوی کاهش مییابد.
ابزارهایی وجود دارند که میتوانند یک پارزر تولید کنند. برای تولید پارزر شما گرامر زبان خود (واژگان و قواعد نحوی) را به این ابزارها میدهید و آنها یک پارزر عملیاتی تولید میکنند. از آنجا که ساخت یک پارزر نیاز به درک عمیقی از فرآیند پارز دارد و ساخت دستی یک پارزر بهینه آسان نیست، تولیدکنندههای پارزر میتوانند بسیار مفید باشند. WebKit از دو ابزار معروف برای تولید پارزر استفاده میکند: Flex برای ساخت لکسر (تحلیلگر واژگانی) و Bison برای ساخت پارزر (تحلیلگر نحوی). ورودی Flex، فایلی است که شامل تعریف عبارات باقاعده (Regular Expressions) برای توکنهاست. ورودی Bison، قواعد نحوی زبان در فرمت BNF است.
پارز کردن HTML
بهطور کلی وظیفه پارزر HTML، تبدیل HTML به درخت پارز است. واژگان و نحو HTML توسط سازمان W3C (World Wide Web Consortium) تعریف شدهاند. همانطور که پیشتر اشاره شد، گرامر نحوی میتواند بهصورت رسمی با فرمتهایی مانند BNF تعریف شود. برخلاف CSS و جاوااسکریپت، پارز کردن HTML را نمیتوان بهراحتی با گرامر مستقل از متن تعریف کرد. برای HTML یک فرمت رسمی بهنام DTD (Document Type Definition) وجود دارد، اما این یک گرامر مستقل از متن نیست.
ممکن است این موضوع در نگاه اول عجیب به نظر برسد، زیرا HTML به XML نزدیک است و برای XML پارزرهای زیادی وجود دارد. تفاوت HTML با XML در این است که، HTML اجازه میدهد برخی تگها حذف شوند و بهطور کلی، نحو HTML در مقایسه با نحو خشک و سختگیر XML، نرمتر است. از یک سو، این دلیل اصلی محبوبیت HTML است زیرا اشتباهات را میبخشد و کار برنامهنویس را آسان میکند. از سوی دیگر، این موضوع نوشتن یک گرامر رسمی را دشوار میکند. پس بهطور خلاصه، HTML را نمیتوان بهراحتی با پارزرهای مرسوم پارز کرد، چون گرامرش مستقل از متن نیست.
فرمت DTD
تعریف HTML در قالب فرمت DTD ارائه شده است. این فرمت برای تعریف زبانهای خانواده SGML استفاده میشود. این فرمت شامل تعریف تمام عناصر مجاز، ویژگیها و سلسلهمراتب آنهاست. همانطور که اشاره شد، DTD برای HTML یک گرامر مستقل از متن ایجاد نمیکند.
چند نسخه مختلف از DTD وجود دارد. صرفا حالت strict، با مشخصات رسمی مطابقت دارد و دیگر حالتها مربوط به پشتیبانی از مارکاپ (Markup)هایی هستند که در گذشته توسط مرورگرها استفاده میشدند. هدف از این کار، سازگاری با محتوای قدیمی است.
الگوریتم پارز
با توجه به اینکه برای پارز HTML نمیتوان از تکنیکهای معمول پارز استفاده کرد، مرورگرها پارزرهای اختصاصی برای پارز HTML ایجاد میکنند. الگوریتم پارز شامل دو مرحله است: توکنسازی (Tokenization) و ساخت درخت.
- توکنسازی همان تحلیل لغوی است، که ورودی را به توکنها تجزیه میکند. از جمله توکنهای HTML میتوان به تگهای شروع، تگهای پایان، نام ویژگیها و مقدار آنها اشاره کرد.
- Tokenizer، توکن را شناسایی کرده و آن را به سازنده درخت میدهد. سپس کارکتر بعدی را برای شناسایی توکن بعدی پردازش میکند و این روند تا انتهای ورودی ادامه دارد.
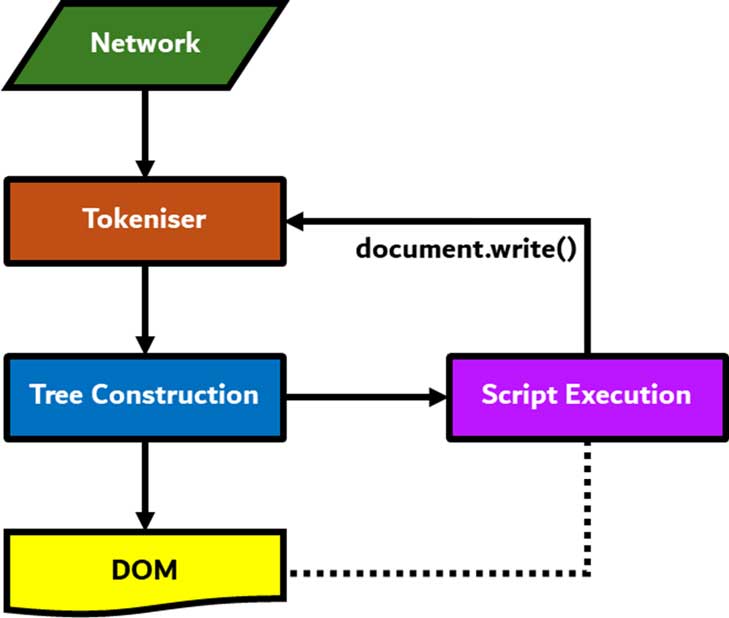
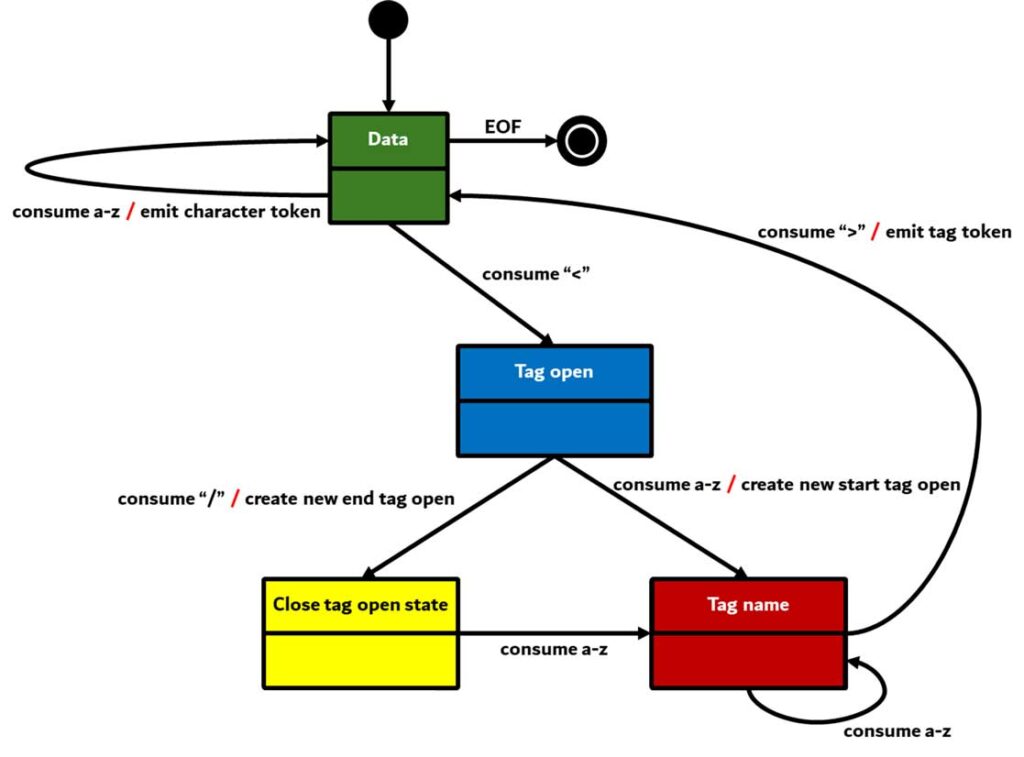
الگوریتم توکنسازی
خروجی این الگوریتم یک توکن HTML است. الگوریتم بهصورت یک state machine بیان میشود. هر حالت، یک یا چند کارکتر را از جریان ورودی خوانده و با توجه به آن، حالت بعدی را تعیین میکند. این تصمیمگیری تحت تاثیر وضعیت فعلی پروسه توکنسازی و همچنین وضعیت ساخت درخت است. یعنی یک کارکتر خوانده شده بسته به وضعیت فعلی، ممکن است نتایج متفاوتی برای تعیین حالت بعدی داشته باشد.
این الگوریتم بسیار پیچیدهتر از آن است که بهطور کامل در اینجا شرح داده شود، بنابراین بیایید یک مثال ساده را بررسی کنیم تا اصول کار را درک کنیم.
<html>
<body>
Hello world
</body>
</html>وضعیت ابتدایی Data state است. زمانی که کاراکتر < خوانده میشود، وضعیت به Tag open state تغییر میکند. خواندن یک حرف a-z باعث تغییر وضعیت به Tag name state میشود. در این وضعیت باقی میمانیم تا زمانی که کاراکتر > خوانده شود. هر کاراکتر به نام توکن جدید افزوده میشود. در مثال ما، توکن ایجادشده یک توکن html خواهد بود.
وقتی به کاراکتر > میرسیم، توکن فعلی به مرحله بعدی میرود و وضعیت به Data state بازمیگردد. تگ <body> نیز مشابه همین مراحل پردازش میشود. تا اینجا، توکنهای html و body پردازش شدهاند. اکنون دوباره در Data state هستیم. خواندن کاراکتر H از “Hello world” باعث ایجاد و ارسال یک توکن کاراکتر میشود و این روند برای هر کاراکتر تا رسیدن به < (مربوط به </body>) ادامه دارد. برای هر حرف از “Hello world” یک توکن از نوع کاراکتر ساخته شده و به مرحله بعد ارسال میشود.
سپس دوباره در وضعیت Tag open state قرار میگیریم. خواندن کاراکتر / باعث ایجاد یک توکن انتهای تگ و تغییر وضعیت به Tag name state میشود. مجددا در این وضعیت میمانیم تا به > برسیم. سپس توکن جدید ارسال میشود و به Data state بازمیگردیم. ورودی </html> نیز مانند مورد قبلی پردازش خواهد شد.
الگوریتم ساخت درخت
وقتی مرورگر یک فایل HTML را پارزر میکند، یک آبجکت اصلی به نام Document ایجاد میکند. این آبجکت مانند ریشه (Root) یک درخت است که تمام عناصر صفحه (مانند تگها، متنها و غیره) به آن متصل میشوند. سازندهی درخت، هر گره را که توسط Tokenizer تولید میشود، پردازش میکند. برای هر توکن، مشخصات فنی مرورگر تعیین میکند که کدام عنصر DOM مرتبط است و باید ساخته شود. هر عنصری که ایجاد میگردد، به طور همزمان به دو محل اضافه میشود، یکی به خود درخت DOM و دیگری به یک ساختار داده پشته. این پشته برای ردیابی تگها توسط مرورگر استفاده میشود و کمک میکند تا خطاهای رایج HTML، مانند فراموش کردن بستن یک تگ یا قرار دادن تگها در جای اشتباه، به صورت خودکار اصلاح شوند. در نهایت، کل این الگوریتم به صورت یک state machine توصیف میشود. این ماشین همواره در یکی از وضعیتهای مشخص به نام insertion modes قرار دارد و تعیین میکند که مرورگر با توکن بعدی چگونه برخورد کند.
برای درک بهتر، نمونه کد HTML قبلی را در نظر بگیرید. ورودی مرحله ساخت درخت، دنبالهای از توکنها از مرحله توکنسازی است. اولین وضعیت، initial mode است. دریافت توکن <html> باعث میشود که به وضعیت before html برویم. پردازش این توکن منجر به ایجاد عنصر HTMLHtmlElement خواهد شد که به آبجکت Document اضافه میشود. سپس وضعیت به before head تغییر میکند. با توجه به کد، در این مرحله توکن <body> دریافت میشود. شایان ذکر است که حتی اگر توکن <head> وجود نداشته باشد، بهطور ضمنی یک عنصر HTMLHeadElement ایجاد میشود و به درخت اضافه میگردد. در این مرحله ابتدا به وضعیت in head و سپس به after head میرویم. توکن <body> پردازش شده و عنصر HTMLBodyElement ایجاد میشود و همچنین وضعیت به in body تغییر پیدا میکند. اکنون توکنهای کاراکتری از رشته “Hello world” دریافت میشوند. اولین کاراکتر منجر به ایجاد یک گره Text میشود و سایر کاراکترها به همین گره اضافه میشوند. پس از دریافت توکن </body> به وضعیت after body میرویم. پس از دریافت توکن پایان HTML، به وضعیت after after body میرویم. در نهایت با دریافت توکن پایان فایل (EOF)، عملیات پارز خاتمه مییابد.
پس از اتمام پارز سند، مرورگر آن را به عنوان Interactive علامتگذاری میکند. سپس شروع به اجرای اسکریپتهایی میکند که در حالت تعویقی (Deferred) قرار دارند، یعنی اسکریپتهایی که پس از پارز کامل سند، باید اجرا شوند. سپس وضعیت سند به Complete تغییر میکند و یک رویداد load اجرا میشود.
پارز کردن CSS
برخلاف HTML، CSS یک گرامر مستقل از متن است و میتوان آن را با استفاده از انواع پارزرهایی که پیشتر توضیح داده شد، پارز کرد.
گرامر واژگانی، توسط عبارات باقاعده برای هر توکن تعریف میشود:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*گرامر نحوی، در فرمت BNF تعریف میشود:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;ترتیب پردازش
مدل وب به صورت همگام (Synchronous) عمل میکند. توسعهدهندگان انتظار دارند زمانی که پارزر به یک تگ <script> میرسد، اسکریپتها فوراً پارز و اجرا شوند. در این حالت، پردازش سند تا پایان اجرای اسکریپت متوقف میشود. اگر اسکریپت اکسترنال باشد، ابتدا باید سورس آن از شبکه دریافت شود. این فرآیند نیز به صورت همگام است و پارز سند تا زمان دریافت کامل سورس از شبکه متوقف میماند. این مدل برای سالها رایج بود و در مشخصات فنی HTML4 و HTML5 نیز به همین صورت تعریف شده است.
البته توسعهدهندگان میتوانند از مشخصه (Attribute) defer برای یک اسکریپت استفاده کنند. در این صورت، اجرای اسکریپت پارز سند را متوقف نکرده و به بعد از اتمام آن، موکول میشود. HTML5 همچنین گزینهای برای مشخص کردن اسکریپت به عنوان ناهمگام (Asynchronous) اضافه کرده است تا اسکریپت توسط یک ترد مجزا پارز و اجرا شود. مرورگرهای مدرن از جمله WebKit و فایرفاکس از این بهینهسازی استفاده میکنند. در حین اجرای اسکریپتها، یک ترد دیگر به صورت موازی شروع به پارز بقیه سند میکند. این ترد سورسهای دیگری را که باید از شبکه دریافت شوند (مانند اسکریپتهای اکسترنال، style sheet ها و تصاویر) شناسایی کرده و فرآیند لود آنها را آغاز میکند. به این ترتیب، سورسها میتوانند بر روی اتصالات (Connections) موازی لود شوند و سرعت کلی صفحه به طور قابل توجهی بهبود مییابد.
Style sheet ها از مدل متفاوتی پیروی میکنند. از نظر مفهومی، به نظر میرسد چون Style sheet ها درخت DOM را تغییر نمیدهند، دلیلی برای متوقف کردن پارز سند (تا بارگیری کامل آنها) وجود ندارد. اما نکته ای که وجود دارد این است که گاهی اسکریپتها در حین پارز سند، به اطلاعات استایل یک عنصر نیاز پیدا میکنند. اگر در آن لحظه Style sheet هنوز لود و پارز نشده باشد، اسکریپت اطلاعات نادرستی دریافت میکند و این موضوع میتواند مشکلات زیادی ایجاد کند. هرچند این وضعیت یک مورد استثنایی به نظر میرسد، اما در عمل بسیار رایج است. به عنوان مثال، فایرفاکس در صورتی که یک Style sheet در حال لود و پارز شدن باشد، اجرای تمام اسکریپت ها را مسدود میکند. WebKit تنها زمانی اجرای اسکریپتها را مسدود می کند که سعی کنند، به ویژگیهای استایلی دسترسی پیدا کنند که ممکن است توسط Style sheet های لود نشده، تحت تاثیر قرار گیرند.
ساخت درخت رندر
در حالی که درخت DOM در حال ساخت است، مرورگر درخت دیگری به نام درخت رندر می سازد. این درخت از عناصر بصری به همان ترتیبی که قرار است نمایش داده شوند، تشکیل شده است و در واقع، نمایش بصری سند محسوب میشود. هدف اصلی این درخت، فراهم کردن امکان ترسیم (Painting) محتوا با ترتیب صحیح است. فایرفاکس به عناصر موجود در درخت رندر، frame میگوید، در حالی که Webkit از اصطلاح renderer یا render object استفاده میکند. هر فریم میداند که چگونه خودش و فرزندانش را جانمایی (Layout) و ترسیم کند. برای نمونه، کلاس RenderObject در Webkit، که کلاس پایه برای تمام فریمها است، به صورت زیر تعریف شده است.
class RenderObject
{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}هر فریم نشاندهنده یک ناحیه مستطیلی است که معمولا با کادر (Box) CSS یک گره مطابقت دارد. این فریم شامل اطلاعات هندسی مانند عرض، ارتفاع و موقعیت است. نوع کادر تحت تاثیر مقدار خصوصیت display در استایل مربوط به آن گره قرار میگیرد. کد زیر از Webkit نشان میدهد که چگونه بر اساس مقدار خصوصیت display، نوع فریم مناسب برای یک گره DOM انتخاب میشود.
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display())
{
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}رابطه درخت رندر با درخت DOM
فریمها با عناصر DOM مطابقت دارند، اما این رابطه همیشه یکبهیک نیست.
- عناصر بدون فریم : عناصر غیربصری DOM در درخت رندر قرار نمیگیرند. برای مثال، عنصر <head> در درخت رندر وجود ندارد. همچنین، عناصری که خصوصیت display آنها برابر با none تنظیم شده باشد، در درخت ظاهر نمیشوند. در مقابل، عناصری با visibility: hidden در درخت رندر وجود دارند، اما صرفا نامرئی هستند.
- یک عنصر با چند فریم : برخی از عناصر DOM به چندین آبجکت بصری تبدیل میشوند. این حالت معمولا برای عناصری با ساختار پیچیده رخ میدهد. برای مثال، عنصر <select> دارای سه فریم است: یکی برای ناحیه نمایش، یکی برای لیست کشویی و یکی برای دکمه. مثال دیگر زمانی است که یک متن طولانی به دلیل کمبود عرض به چند خط شکسته میشود، هر خط جدید به عنوان یک فریم مجزا در نظر گرفته میشود.
- فریمهای ناشناس : طبق قوانین چیدمان CSS، یک عنصر نمیتواند به طور همزمان فرزندان از نوع inline و block را در کنار هم داشته باشد. در صورتی که چنین محتوای ترکیبی و نامعتبری در کد وجود داشته باشد، مرورگر برای اصلاح آن به طور خودکار فریمهای ناشناس ایجاد میکند. این فریمهای نامرئی، محتوای inline را در بر میگیرند تا آن را از محتوای بلاکی جدا کرده و ساختار را برای نمایش تصحیح کنند.
- فریمهای خارج از جریان: برخی از فریمها متعلق به یک گره DOM هستند اما در جایگاه متفاوتی از درخت رندر قرار میگیرند. عناصر شناور (Float) و عناصری که موقعیت مطلق دارند، خارج از جریان اصلی صفحه قرار میگیرند. این عناصر به بخش دیگری از درخت رندر منتقل میشوند، در حالی که یک فریم placeholder در مکان اصلی آنها باقی میماند.
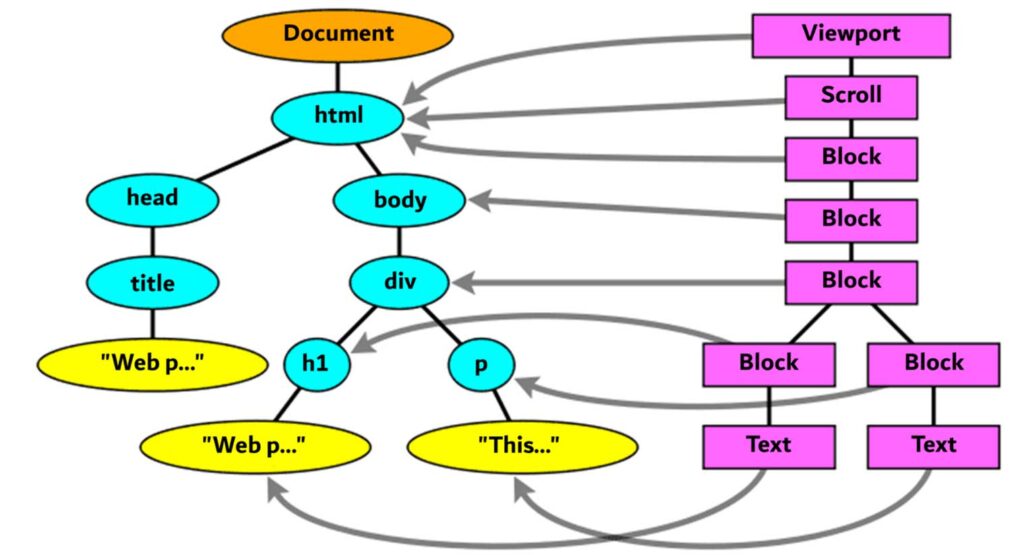
چیدمان
هنگامی که یک فریم ساخته شده و به درخت اضافه میشود، هنوز موقعیت و اندازهای ندارد. محاسبه این مقادیر، چیدمان یا Reflow نامیده میشود. HTML از یک مدل چیدمان مبتنی بر جریان (Flow-based) استفاده میکند، به این معنی که در اغلب موارد، اطلاعات هندسی را میتوان با یک بار عبور محاسبه کرد. هندسه عناصری که در ابتدای جریان هستند، معمولا از عناصری که در ادامهی جریان قرار دارند، تأثیر نمیپذیرد. بنابراین چیدمان میتواند از چپ به راست و از بالا به پایین در سند پیش برود. البته استثنائاتی نیز وجود دارد، برای مثال جداول HTML ممکن است به بیش از یک بار عبور نیاز داشته باشند.
سیستم مختصات نسبت به فریم ریشه است، که از مختصات بالا و چپ استفاده میکند. فرآیند چیدمان به صورت بازگشتی (Recursive) است. این فرآیند از فریم ریشه (که مربوط به عنصر <html> است)، آغاز میشود و به صورت بازگشتی در تمام یا بخشی از فریمها ادامه مییابد و اطلاعات هندسی را برای هر فریمی که به آن نیاز دارد، محاسبه میکند. موقعیت فریم ریشه 0,0 و ابعاد آن برابر با viewport (یعنی بخش قابل مشاهده پنجره مرورگر) است. تمام فریمها یک متد reflow یا layout دارند و هر فریم، این متد را برای فرزندان خود که نیاز به چیدمان مجدد دارند، فراخوانی میکند.
انواع چیدمان
چیدمان میتواند بر روی کل درخت رندر اجرا شود که به آن چیدمان سراسری (Global) میگویند. این حالت ممکن است در نتیجه یک تغییر استایل سراسری (مانند تغییر اندازه فونت) که بر تمام فریمها تاثیر میگذارد، یا در نتیجه تغییر اندازه صفحه نمایش رخ دهد.
چیدمان همچنین میتواند افزایشی (Incremental) باشد، به این معنی که فقط فریمهای کثیف دوباره چیده میشوند. در واقع چیدمان افزایشی، به صورت ناهمگام و زمانی که فریمها کثیف میشوند، فعال میگردد. برای مثال، هنگامی که محتوای جدیدی از شبکه دریافت شده و به درخت DOM اضافه میشود، فریمهای جدیدی نیز به درخت رندر ضمیمه میشوند و این نوع چیدمان را فعال میکنند.
همانطور که اشاره شد، چیدمان افزایشی به صورت ناهمگام انجام میشود. فایرفاکس دستورات reflow را برای چیدمانهای افزایشی، در یک صف قرار میدهد و یک scheduler، اجرای گروهی این دستورات را مدیریت میکند. در مقابل، اسکریپتهایی که اطلاعات استایل را درخواست میکنند (مانند offsetHeight)، میتوانند یک چیدمان افزایشی را به صورت همگام فعال کنند. چیدمان سراسری نیز معمولا به صورت همگام اجرا میشود.
بهینهسازیها
برای جلوگیری از اجرای یک چیدمان کامل به ازای هر تغییر کوچک، مرورگرها از یک سیستم به نام dirty bit استفاده میکنند. هر فریمی که تغییر میکند یا به تازگی اضافه میشود، خود و فرزندانش به عنوان “کثیف” علامتگذاری میشوند، به این معنی که نیاز به چیدمان مجدد دارد. برای این کار دو فلگ وجود دارد: فلگ اول dirty و فلگ دوم children are dirty است. این بدان معناست که اگرچه ممکن است خود فریم مشکلی نداشته باشد، اما حداقل یکی از فرزندانش نیاز به چیدمان دارد.
هنگامی که یک چیدمان به دلیل تغییر سایز یا تغییر در موقعیت یک فریم فعال میشود، سایز فریمها از کش خوانده شده و دوباره محاسبه نمیشود. علاوه بر این، در برخی موارد تنها یک زیردرخت (Sub-tree) اصلاح میشود و چیدمان از ریشه آغاز نمیگردد. این حالت زمانی رخ میدهد که تغییر، محلی (Local) بوده و بر محیط اطراف خود تاثیر نمیگذارد. مانند زمانی که محتوا در یک فیلد متنی وارد میشود، در غیر این صورت هر بار فشردن یک کلید باعث اجرای چیدمان از ریشه میشد.
فرآیند چیدمان
چیدمان معمولا الگوی زیر را دنبال میکند:
- فریم والد عرض خود را مشخص میکند.
- والد به سراغ فرزندان میرود:
- موقعیت فریم فرزند را مشخص میکند (مقداردهی x و y آن).
- در صورت نیاز، تابع layout فرزند را فراخوانی میکند (مثلا اگر آنها کثیف باشند، یا در یک چیدمان سراسری باشیم).
- والد از مجموع ارتفاعات فرزندان، ارتفاعات حاشیهها و padding برای تنظیم ارتفاع خود استفاده میکند. این مقدار بعدا توسط فریم والد این فریم استفاده خواهد شد.
- بیت dirty خود را به false تغییر میدهد.
فایرفاکس از یک آبجکت state (بهصورت nsHTMLReflowState) به عنوان پارامتری برای تابع layout استفاده میکند. این آبجکت شامل مواردی از جمله عرض والد است. خروجی فرآیند چیدمان در فایرفاکس، یک آبجکت metrics (بهصورت nsHTMLReflowMetrics) است که شامل ارتفاع محاسبهشده فریم خواهد بود. عرض یک فریم با استفاده از عرض بلوک دربرگیرنده، ویژگی width در استایل فریم و حاشیهها و کادرهای آن، محاسبه میشود.
ترسیم
در مرحله ترسیم، درخت رندر پیمایش شده و متد paint() هر فریم، برای نمایش محتوا روی صفحه فراخوانی میشود. این فرآیند از مولفههای رابط کاربری استفاده میکند. ترسیم میتواند سراسری یا افزایشی باشد. در ترسیم سراسری، کل درخت ترسیم میشود. در ترسیم افزایشی، برخی از فریمها تغییر میکنند اما بر کل درخت تاثیر نمیگذارد. در واقع به جای اینکه برای هر تغییر کوچک کل صفحه را از نو ترسیم کنیم، فقط همان بخشهای تغییرکرده را هوشمندانه و به صورت بهینه دوباره ترسیم میکنیم.
ترتیب ترسیم
ترتیب فرآیند ترسیم در مشخصات CSS2 تعریف شده است. این ترتیب، در واقع مشابه ترتیبی است که عناصر در استک چیده میشوند. از آنجایی که این پشتهها از عقب به جلو ترسیم میشوند، ترتیب آنها بر خروجی نهایی تأثیرگذار است. ترتیب ترسیم برای یک فریم بلاکی به شرح زیر است:
- رنگ پسزمینه
- تصویر پسزمینه
- حاشیه (Border)
- فرزندان
- طرح کلی (Outline)
فایرفاکس درخت رندر را پیمایش کرده و یک لیست نمایش برای مستطیل مورد نظر میسازد. این لیست حاوی فریمهای مرتبط با آن مستطیل، همراه با ترتیب صحیح ترسیم (ابتدا پسزمینهها، سپس حاشیهها و غیره) است. بدین ترتیب برای یک ترسیم مجدد، درخت فقط یکبار پیمایش میشود. Webkit قبل از ترسیم مجدد، مستطیل قدیمی را به صورت یک bitmap ذخیره میکند. سپس فقط تفاوت بین مستطیل جدید و قدیمی را ترسیم میکند.
رویکرد مرورگرها
مرورگرها تلاش میکنند در واکنش به یک تغییر، کمترین اقدام ممکن را انجام دهند. به همین دلیل، تغییر رنگ یک عنصر تنها باعث ترسیم مجدد همان عنصر میشود، در حالی که تغییر موقعیت آن، نیازمند چیدمان و ترسیم مجدد خود عنصر، فرزندانش و احتمالا همسطحهایش (Siblings) است. به همین ترتیب، افزودن یک گره DOM جدید نیز باعث چیدمان و ترسیم مجدد آن گره خواهد شد. البته تغییرات بزرگ، مانند افزایش سایز فونت عنصر <html>، بسیار پرهزینهتر بوده و منجر به نامعتبرسازی کشها و ترسیم مجدد کل درخت میشود.
موتور رندر، تک تردی است و تقریبا همه چیز بهجز عملیات شبکه، در یک ترد واحد اتفاق میافتد. این ترد واحد در مرورگرهای فایرفاکس و سافاری همان ترد اصلی مرورگر است، اما در کروم به ترد اصلی پروسه تب، اختصاص دارد. برخلاف موتور رندر، عملیات شبکه میتواند توسط چندین ترد موازی انجام شود، هرچند تعداد این اتصالات موازی معمولا به 2 تا 6 عدد محدود است.
ترد اصلی مرورگر یک حلقه رویداد (Event Loop) است. این یک حلقه بینهایت است که پروسه را زنده نگه میدارد و منتظر رویدادها (از جمله رویدادهای چیدمان و ترسیم) میماند تا آنها را پردازش کند. کد زیر، حلقه رویداد اصلی در فایرفاکس را نشان میدهد:
while (!mExiting)
NS_ProcessNextEvent(thread);مدل فرمتدهی بصری
در CSS، مدل فرمتدهی بصری توصیف میکند که چگونه مرورگرها درخت سند را پردازش کرده و آن را در مانیتور نمایش میدهند. در این مدل، هر عنصر در درخت سند، صفر یا چند جعبه را بر اساس مدل جعبهای (Box Model) ایجاد میکند. کنترل چیدمان این جعبهها توسط عواملی مانند، ابعاد و نوع جعبهها، روابط بین گرهها در درخت سند و اطلاعات خارجی (مانند اندازه viewport یا ابعاد ذاتی تصاویر) انجام میشود.
بخش بزرگی از اطلاعات مربوط به مدل فرمتدهی بصری در CSS2 تعریف شده است. طبق مشخصات CSS2، اصطلاح بوم (Canvas) فضایی را توصیف میکند که ساختار فرمتدهی در آن نمایش داده میشود. بوم از نظر تئوری در هر بعد بینهایت است، اما مرورگرها بر اساس ابعاد viewport یک عرض اولیه برای آن انتخاب میکنند. Viewport همان ناحیه قابل مشاهده در پنجره مرورگر است. مرورگرها میتوانند با تغییر اندازه viewport، چیدمان صفحه را تغییر دهند. اگر viewport از اندازه کل سند کوچکتر باشد، مرورگر باید راهی برای اسکرول کردن به بخشهایی از سند که نمایش داده نمیشوند، فراهم کند.
مدل جعبهای CSS
مدل جعبهای CSS، توصیفکننده جعبههای مستطیلی است که برای عناصر موجود در درخت سند ایجاد شده و طبق مدل فرمتدهی بصری چیده میشوند. هر جعبه دارای یک ناحیه محتوا (مانند متن و تصویر) و به صورت اختیاری، نواحی پیرامونی padding، border و margin است.
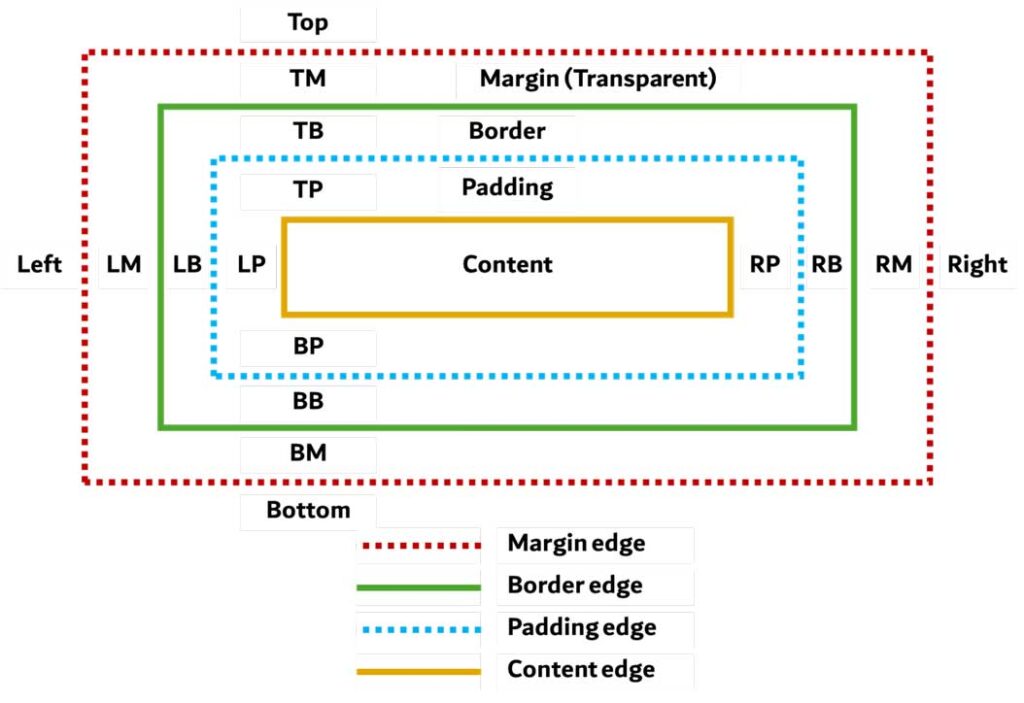
هر گره در سند میتواند از صفر تا چند جعبه از این نوع ایجاد کند. تمام عناصر دارای یک خصوصیت display هستند که نوع جعبهای که باید ایجاد شود را مشخص میکند. برای مثال، مقدار block یک جعبه بلاکی، مقدار inline یک یا چند جعبه درونخطی و مقدار none هیچ جعبهای ایجاد نمیکند. مقدار پیشفرض این خصوصیت inline است، اما style sheet مرورگر ممکن است مقادیر پیشفرض دیگری را تنظیم کند. برای مثال، مقدار display پیشفرض عنصر <div> برابر با block است.
نحوه موقعیتدهی (Positioning Scheme)
سه روش اصلی برای موقعیتدهی وجود دارد:
- عادی : در این روش آبجکت بر اساس جایگاهش در سند موقعیتدهی میشود. در واقع جایگاه آبجکت در درخت رندر، مانند جایگاهش در درخت DOM است و بر اساس نوع و ابعاد جعبهاش چیده میشود.
- شناور : در این روش آبجکت ابتدا مانند روند عادی چیده شده و سپس تا جای ممکن به چپ یا راست منتقل میشود.
- مطلق : در این روش آبجکت در جایی از درخت رندر، متفاوت از جایگاهش در درخت DOM قرار میگیرد.
نحوه موقعیتدهی توسط خصوصیت position و float تنظیم میشود. مقادیر static و relative برای خصوصیت position باعث “موقعیتدهی عادی” و مقادیر absolute و fixed باعث “موقعیتدهی مطلق” میشوند. در موقعیتدهی مطلق، هیچ موقعیتی تعریف نمیشود و از چیدمان پیشفرض استفاده میشود، اما در سایر روشها، نویسنده موقعیت را با استفاده از خصوصیات top، bottom، left و right مشخص میکند. نحوه چیدمان یک جعبه توسط عواملی مانند نوع جعبه، ابعاد جعبه، نحوه موقعیتدهی و اطلاعات خارجی (مانند اندازه تصویر و اندازه صفحه) تعیین میشود.
انواع جعبه
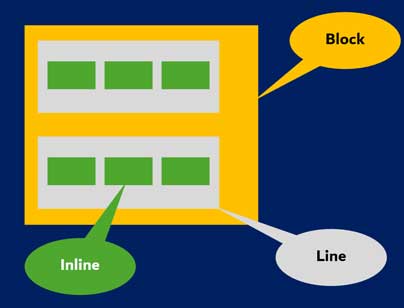
جعبه بلاکی یک بلوک تشکیل میدهد، یعنی در پنجرهی مرورگر، مستطیل جداگانهای دارد.

جعبه inline بلوک جداگانهای ندارد، بلکه درون یک بلوک والد قرار دارد.
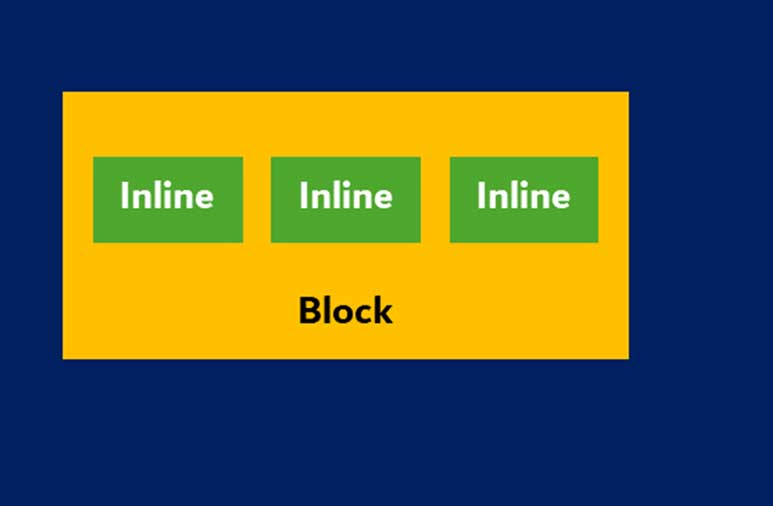
بلوکها به صورت عمودی و یکی پس از دیگری چیده میشوند، در حالی که عناصر inline به صورت افقی فرمتدهی میشوند.

جعبههای inline داخل خطوطی به نام line box قرار میگیرند. ارتفاع این خطوط حداقل به اندازه بلندترین جعبه درون آنهاست. اگر عرض این فضا کافی نباشد، عناصر inline در چندین خط قرار میگیرند. این همان اتفاقی است که معمولا در یک پاراگراف رخ میدهد.
نمایش لایهای
این مفهوم توسط خصوصیت z-index در CSS مشخص میشود و نشاندهنده بعد سوم یک جعبه است (یعنی موقعیت آن در امتداد محور z). در این مدل، جعبهها به دستههایی مانند استکها تقسیم میشوند. در هر استک، عناصر پشتی زودتر ترسیم میشوند و عناصر جلویی روی آنها قرار میگیرند. در صورت همپوشانی، عنصری که جلوتر است، عنصر قبلی را پنهان میکند. ترتیب این پشتهها بر اساس مقدار خصوصیت z-index تعیین میشود. نمونه زیر را در نظر بگیرید:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>نتیجه نمونه کد بالا بهصورت زیر است:

اگرچه div قرمز در کد HTML قبل از div سبز آمده و در روند عادی ابتدا رسم میشد، اما به دلیل اینکه مقدار خصوصیت z-index آن بیشتر است، در موقعیتی جلوتر (نزدیکتر به کاربر) قرار میگیرد.
ارجاعات
- https://firefox-source-docs.mozilla.org/overview/gecko.html
- https://firefox-source-docs.mozilla.org/layout/index.html
- https://www-archive.mozilla.org/newlayout/doc/gecko-overview.htm
- https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_display/Visual_formatting_model
- https://web.dev/articles/howbrowserswork
- https://dbaron.github.io/browser-rendering
- https://www.youtube.com/watch?v=a2_6bGNZ7bA
- https://www.youtube.com/watch?v=SyUBuio_ooE