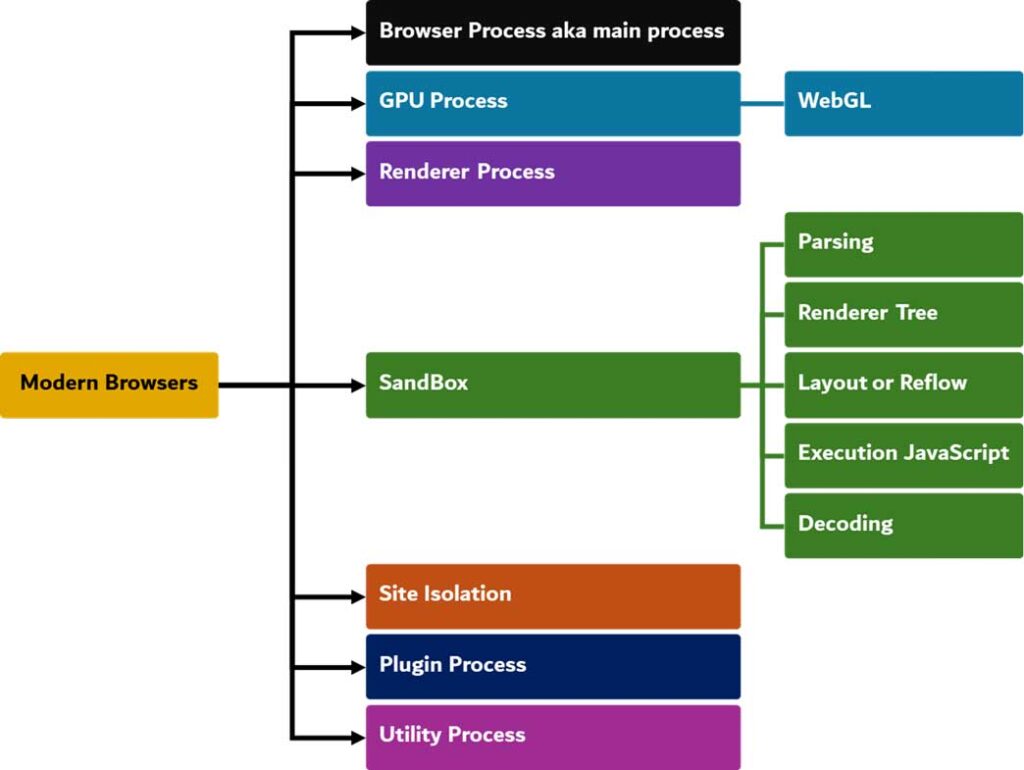
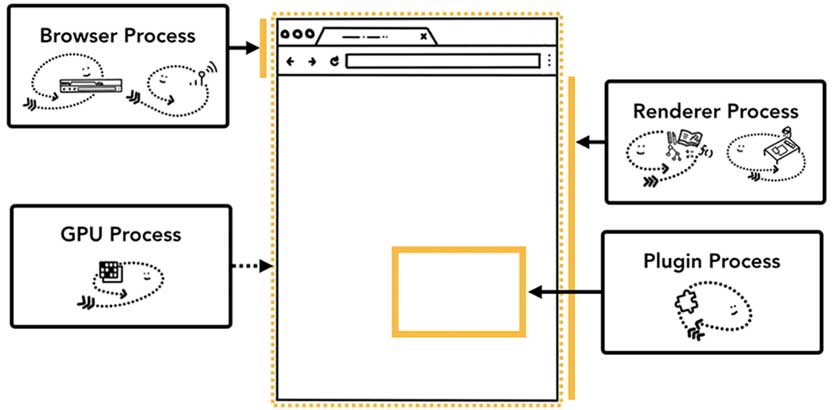
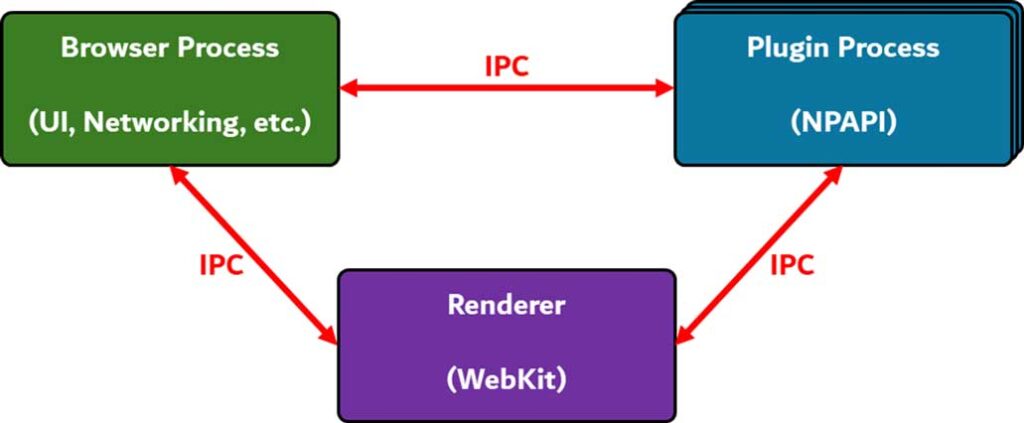
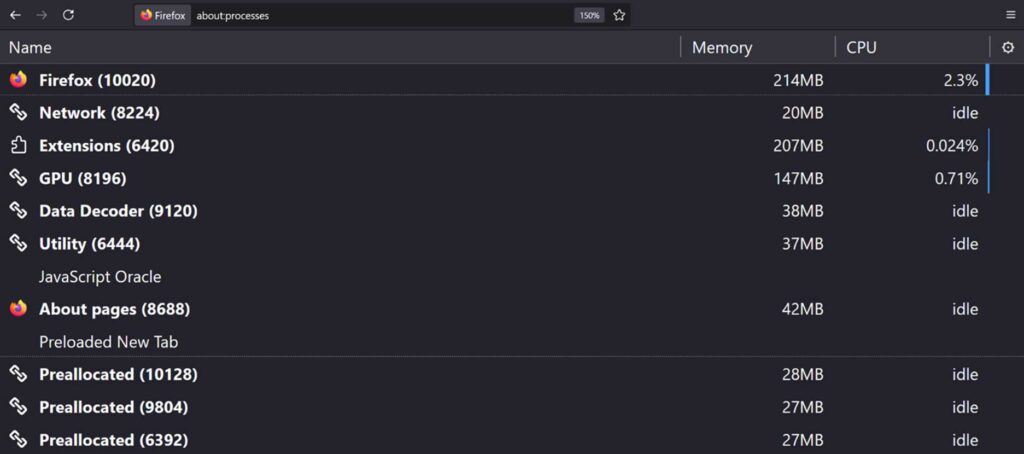
حال به بررسی فرآیند طیشده از زمان درخواست یک URL در نوار جستجو (Search Bar) تا زمان نمایش محتوا در مرورگر خواهیم پرداخت. اگر به اینترنت متصل نباشیم، مرورگر ابتدا حافظه cache خود را بررسی کرده و در صورتی که نسخهای از آن محتوا در آن ذخیره شده باشد، آن را بارگذاری خواهد کرد. این امر به تنظیمات هدرهایی مانند Pragma و Cache-Control در سایت مورد نظر نیز بستگی دارد.
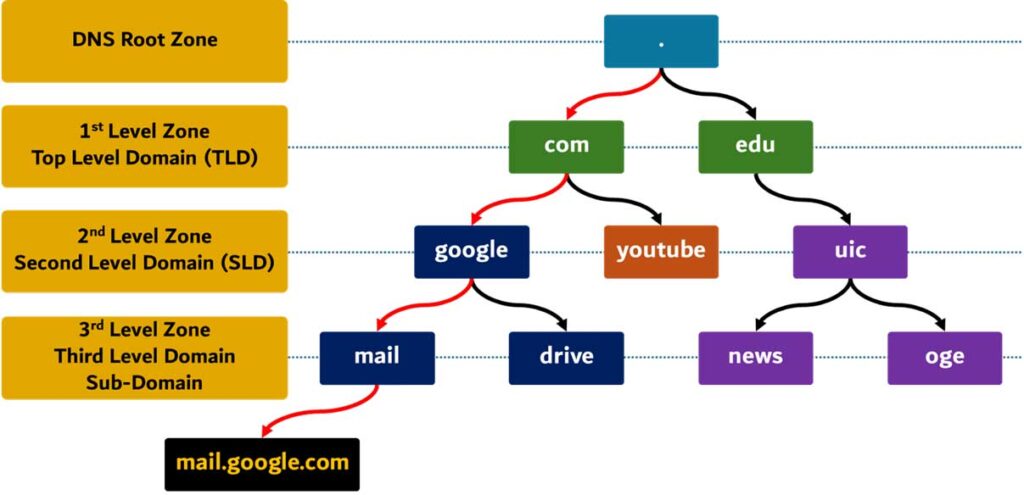
حال فرض کنید که به اینترنت متصل هستیم و سایت example.com را جستجو کردهایم. در این شرایط، ابتدا مرورگر به سراغ فایل hosts در سیستمعامل میرود و بررسی میکند که آیا IP دامنه example.com در آن موجود است یا خیر. اگر IP سایت مذکور موجود باشد، آن را resolve میکند. در صورتی که وجود نداشته باشد، مرورگر از استانداردی به نام getname-info برای انجام Name Resolving استفاده میکند. برای این کار، بسته به نوع سیستمعامل، به سراغ DNS Server تنظیمشده میرود و در صورتی که IP مورد نظر در حافظه کش آن موجود باشد، آن را باز میگرداند. در غیر این صورت، به سراغ Root Servers میرود (در کل 13 سرور Root در جهان وجود دارد).
برای مثال، اگر بخواهیم IP سایت example.com را پیدا کنیم، ابتدا Root Server به سراغ Top Level Domain میرود که در اینجا .com است، سپس در Second Level Domain ها دنبال دامنه example میگردد. پس از پیدا کردن IP دامنه مذکور، عملیاتهای بعدی مانند TCP Handshake و TLS Handshake انجام میشود و در نهایت نتیجه در مرورگر نمایش داده خواهد شد.