

ماژول 2: بررسی معماری و اندرونیات مرورگرها
در این سند به بررسی و مطالعه معماری مرورگرها با تمرکز بر محصول Mozilla Firefox خواهیم پرداخت
نویسنده: رضا احمدی
تاریخ انتشار: 25 اردیبهشت 1404
فهرست
مقدمه
مرورگرهای وب از جمله بزرگترین و پیچیدهترین نرمافزارهای ساخته شده تا به امروز هستند. برای درک کلی از مقیاس آنها، میتوان به موتور مرورگر سافاری (WebKit) با حدود 32 میلیون خط کد، و کرومیوم (Chromium) با حدود 44 میلیون خط کد، و فایرفاکس با حدود 25 میلیون خط کد اشاره نمود. از آنجا که خواندن N میلیون خط کد، نه لذتبخش است و نه عملی، در ادامه مرورگر را به بخشهای مفهومی آن تقسیم خواهیم کرد، تا بتوانیم در فرایند ارزیابی کد (Code Audit)، بر روی قسمتهای مهم تمرکز کنیم.
مروری بر ساختار مرورگرها
مرورگر را میتوان به دو بخش بروکر (Broker) و رندرر (Renderer) تقسیم کرد. این جداسازی منطقی بین بروکر و رندرر، یک کرانه امنیتی (Security boundary) نیز محسوب میشود. ذاتاً رندرر باید دادههای HTML و جاوااسکریپت دلخواه و غیرقابل اعتماد را پردازش کند که هر دو بهصورت بالقوه دارای پیچیدگی هستند. به همین دلیل، بخش عمدهی آسیبپذیریها در رندرر متمرکز خواهند بود. معمولا فرایند اکسپلویت کردن این آسیبپذیریها، به این صورت است که محتوای وب طراحیشدهی بخصوصی نوشته میشود، تا باگهای درون رندرر تریگر شوند، و سپس از این باگها برای اعمالی مانند اجرای کد از راهدور (Remote Code Execution) استفاده میشود.
در ادامهی این موضوع، ممکن است این پرسش پیش بیاید که، این کرانه امنیتی چگونه اجرا یا پیادهسازی میشود، چرا که به نظر میرسد هر دو این مؤلفهها در یک برنامه واحد قرار دارند. رویکرد متداول امروزی ایزولهسازی است که با قرار دادن مؤلفههای پرخطر (مانند رندرر) در پروسههای مستقل انجام میشود. این موضوع را به سادگی میتوان با مشاهده پروسه مرورگر در Task Manager بررسی کرد (تصویر 1).
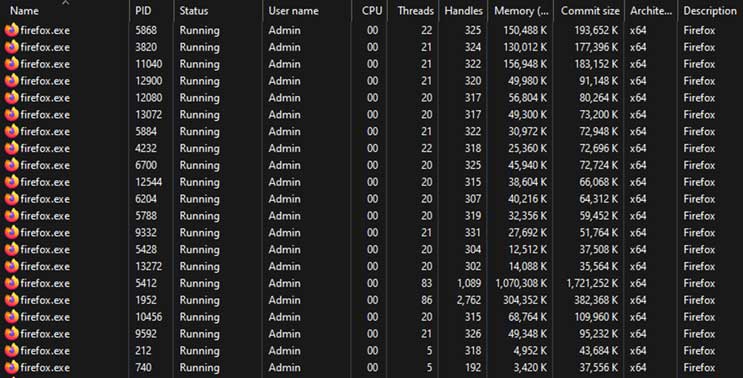
با توجه به تصویر 1، با این که صرفا یک نمونه از فایرفاکس در حال اجراست، بیش از چند پروسه توسط مرورگر ایجاد شده است. در لینوکس نیز با استفاده از دستور ps fx، میتوان این سلسله مراتب را مشاهده کرد (تصویر 2).
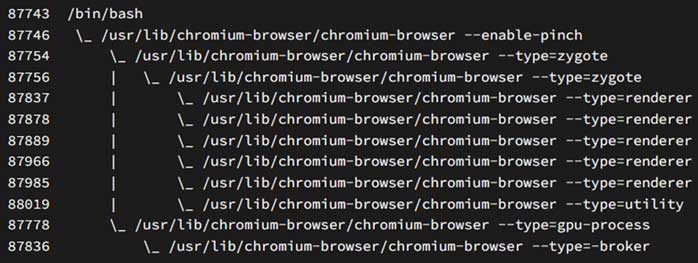
با توجه به تصویر بالا، انواع پروسه کرومیوم در بخش –type قابل مشاهده است. اکثر این پروسهها از نوع رندرر هستند. این منطقی است، زیرا رندرر مسئول نمایش و پردازش تقریباً تمام محتوای وب است. به همین دلیل گاهی به آن Content Process میگویند. این یعنی برای هر صفحه وب (تب مرورگر) به یک رندرر جدید نیاز است. قراردادن محتواهای غیرقابل اعتماد در فرآیندهای جداگانه، ثبات مرورگر را افزایش میدهد. نکته دیگر این است که پروسههای رندرر معمولاً سندباکس میشوند.
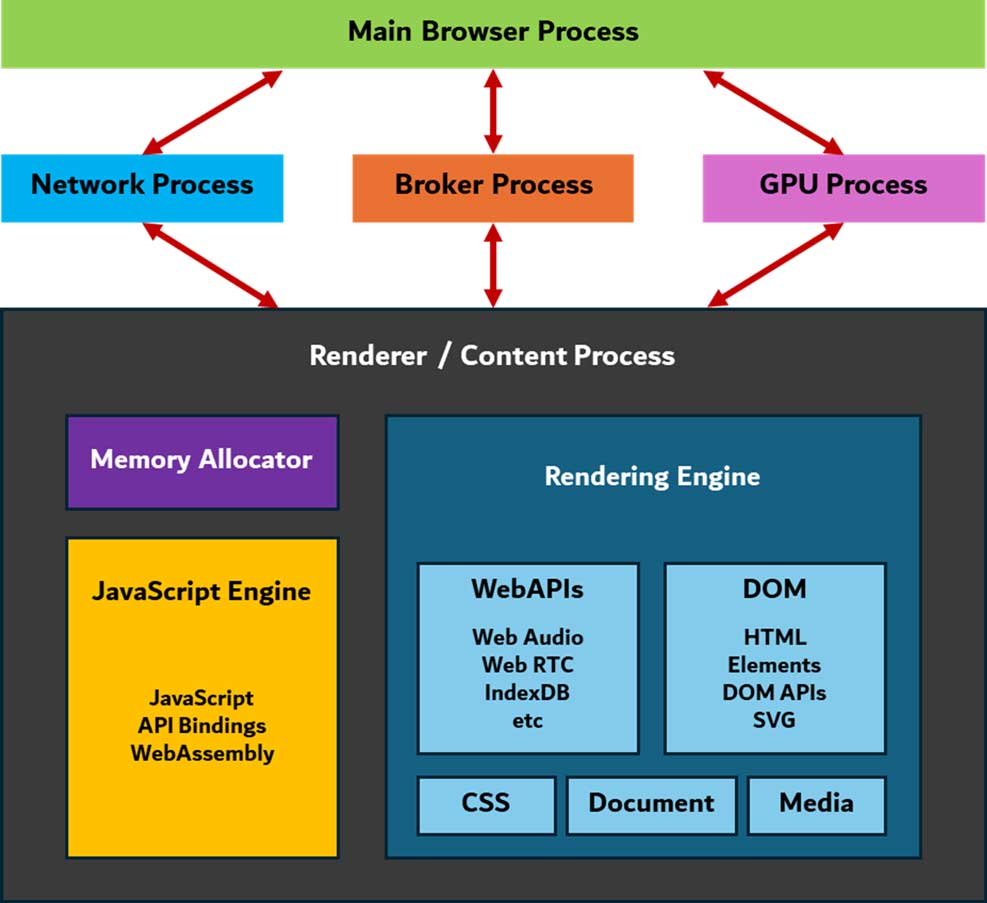
با توجه تصویر 3، میتوانیم بخشهای اصلی تشکیلدهنده رندرر را مشاهده کنیم. اجزای نمایش داده شده اساساً از نامشان هدفشان مشخص است. بهطور کلی هر یک به زیرمجموعههای دیگری نیز تقسیم میشوند که اهداف خاصی را محقق میسازند.
استاندارد Web Interface Description Language (WebIDL)
WebIDL فرمتی استاندارد برای تعریف APIها بین اجزای مختلف مرورگر ارائه میدهد، و اجزا را قادر میسازد تا با یکدیگر ارتباط برقرار کنند. در فرآیند بیلد (Build)، WebIDLها به صورت خودکار به کد C++ تبدیل میشوند و سایر اجزا میتوانند فایلهای هدر حاصل را برای ارتباط با یک مولفه خاص include کنند. در ادامه یک نمونه فایل WebIDL آورده شده است:
[Constructor, Exposed=Window]
interface Document : Node {
[SameObject] readonly attribute DOMImplementation implementation;
readonly attribute USVString URL;
readonly attribute USVString documentURI;
readonly attribute USVString origin;
readonly attribute DOMString compatMode;
readonly attribute DOMString characterSet;
readonly attribute DOMString charset; // historical alias of .characterSet
readonly attribute DOMString inputEncoding; // historical alias of .characterSet
readonly attribute DOMString contentType;
readonly attribute DocumentType? doctype;
readonly attribute Element? documentElement;
HTMLCollection getElementsByTagName(DOMString qualifiedName);
HTMLCollection getElementsByTagNameNS(DOMString? namespace, DOMString localName);
HTMLCollection getElementsByClassName(DOMString classNames);
...
نمونه 1: یک نمونه فایل WebIDL
شایان ذکر است که کدهای C++ ایجاد شده مربوط به WebIDLها در دایرکتوری build قرار خواهند گرفت. معمولاً مطالعه آنها ارزش زمانی ندارد. اگر به دنبال باگ در کدهای Auto Generated هستید، باید Generatorهای کد را بررسی کنید. در ادامه، تمرکز ما بر روی کامپایل مرورگر فایرفاکس خواهد بود. اگرچه مستقیماً WebIDLها را تغییر یا مورد استفاده قرار نمیدهیم، اما داشتن درک کلی از چیستی آنها، به شفافسازی مکانیک ادغام مولفههای مختلف با یکدیگر کمک میکند.
مولفههای مهم مرورگرها
تا اینجا، ما به بررسی موضوعات مختلفی پرداختیم تا تصویر کلی از معماری مرورگرهای امروزی ترسیم کنیم. قبل از پرداختن به جنبههای عملی بیلد مرورگر فایرفاکس، یک معرفی از مرورگرهای مطرح خواهیم داشت.
مرورگر سافاری (WebKit)
سافاری، مرورگر پیشفرض محصولات اپل است که توسط این شرکت توسعه داده میشود. تقریباً تمام مرورگر سافاری بر پایه WebKit ساخته شده است، و میتوان گفت یک پوشش حول موتور WebKit میباشد که تغییرات مربوط به سیستمعاملهای اپل به آن اضافه شده است.
ریشههای WebKit به پروژه داخلی اپل به نام KHTML در سال 2001 بازمیگردد. این پروژه در سال 2005 اوپنسورس شد و به پروژه WebKit تبدیل گردید. دو جزء اصلی WebKit عبارتند از:
- WebCore: موتور رندرینگ
- JavaScriptCore: موتور جاوا اسکریپت
استفاده از WebKit در پروژههای دیگر نیز رایج است. از این موارد میتوان به مرورگرهای مربوط به کنسولهای نینتندو (Nintendo)، پلیاستیشن (Playstation) سونی، و کیندل (Kindle) آمازون اشاره کرد. همانند اپل، این پروژهها نیز WebKit را متناسب با تنظیمات و پیادهسازیهای سختافزاری خود ترکیب میکنند.
مرورگر کروم
کروم احتمالاً شناختهشدهترین مرورگر جهان و قطعاً پراستفادهترین مرورگر در سیستمهای دسکتاپ است. کروم بر پایه موتور Chromium ساخته شده که مانند WebKit اوپنسورس است و گوگل آن را در سال 2008 منتشر کرد. اجزای اصلی کروم عبارتند از:
- Blink: موتور رندرینگ
- در ابتدا از WebCore(در پروژه WebKit) استفاده میکرد که در سال 2013 انشعاب (Fork) یافت.
- V8: موتور جاوا اسکریپت
مانند WebKit، بسیاری از پروژهها از کرومیوم استفاده میکنند. از این موارد میتوان به مرورگرهای مربوط به خودروهای تسلا (Tesla) و تلویزیونهای هوشمند سامسونگ اشاره کرد.
مرورگر فایرفاکس
فایرفاکس یک مرورگر وب اوپنسورس است که توسط بنیاد موزیلا (Mozilla) توسعه داده میشود. این مرورگر بهعنوان یکی از معدود مرورگرهای مستقل از کرومیوم شناخته میشود. فایرفاکس در ابتدا بهعنوان شاخهای از پروژه Netscape با نام Mozilla Application Suite آغاز به کار کرد. در سال 2002، موزیلا تصمیم گرفت یک مرورگر سبکتر و سریعتر بسازد که نتیجه آن Firefox 1.0 بود که در سال 2004 عرضه شد. فایرفاکس از چندین جزء کلیدی تشکیل شده است:
- Gecko: موتور رندرینگ
- SpiderMonkey: موتور جاوا اسکریپت
مانند کرومیوم و WebKit، فایرفاکس نیز در پروژههای دیگر استفاده میشود. مواردی مانند مرورگر TOR و همچنین مرورگرهای سازمانی و دولتی که نیاز به کنترل بیشتر روی حریمخصوصی دارند.
بیلد مرورگرها
با وجود پیچیدگی زیاد، مرورگرهای وب نیز مانند هر پروژه نرمافزاری دیگری قابل ساخت و تحلیل هستند. از آنجا که مرورگر فایرفاکس کاملاً اوپنسورس است، دو مزیت اصلی به همراه دارد:
- امکان دانلود و بیلدکردن نسخه شخصی برای دیباگ
- عدم نیاز به مهندسی معکوس باینریهای مرورگر
بیلدکردن پروژههای بزرگ از سورسکد میتواند چالشبرانگیز باشد. در این بخش، فرآیند بیلد مرورگر فایرفاکس را مورد بررسی قرار داده و نکات کلیدی مربوط به پژوهش آسیبپذیری را تشریح میکنیم.
انواع بیلد
بهطور کلی دو نوع بیلد مهم وجود دارد: Release و Debug. اگرچه هر دو از نظر فنی از کد یکسانی تشکیل شدهاند، اما تفاوتهای بسیاری در پیکربندی آنها وجود دارد.
نسخه Release
نسخه Release اساساً مشابه چیزی است که بهعنوان بیلدهای رسمی به کاربران ارائه میشود. بهعنوان مثال، هنگام دانلود و نصب فایرفاکس روی یک سیستم، در حال کار با بیلدی از فایرفاکس هستید که تحت حالت Release کامپایل شده و همچنین تغییرات مختص به پلتفرم روی آن اعمال شده است. از ویژگیهای بیلد Release میتوان به موارد زیر اشاره کرد:
- کاهش حجم باینری با حذف تمام سیمبلها (Symbol)
- اعمال بهینهسازیهای بیشتر در زمان کامپایل
- عدم وجود بررسیهای اضافه، مربوط به دیباگ
در نهایت این باعث میشود باینریها برای کاربران نهایی بسیار کوچکتر و سریعتر باشند.
نسخه Debug
برخلاف بیلد Release، بیلدهای Debug عمدتاً برای توسعهدهندگان طراحی شدهاند. بیلدهای دیباگ معمولاً عملکرد و سرعت را فدای دسترسی به حجم زیادی از اطلاعات مرتبط با فرآیند میکنند، که به طور دائم در دسترس هستند. از ویژگیهای بیلد دیباگ میتوان به موارد زیر اشاره کرد:
- ایجاد باینریهای حجیم:
- وجود سیمبلها و اطلاعات دیباگ بهصورت کامل
- کد و ویژگیهای اضافی منحصر به حالت دیباگ
- وجود دستورات و بررسیهای دیباگ در کد کامپایل شده
- صرفا اعمال بهینهسازیهای محتاطانه
در نهایت یک بیلد دیباگ احتمالاً بهطور محسوسی کندتر اجرا میشود، اما برای اهدافی مانند پژوهش آسیبپذیری بسیار مفید است.
بیلد فایرفاکس
مستندات رسمی موزیلا برای بیلد فایرفاکس در بخش ارجاعات قابل دسترسی است [1]. با این حال، در ادامه مراحل اصلی بیلد در سیستمعامل لینوکس بررسی خواهد شد. در نظر داشته باشید که به دلیل حجم بالای دادهها، ممکن است پروسه دانلود و بیلد زمانبر باشد. حداقل مشخصات یک سیستم مناسب برای بیلد فایرفاکس به صورت زیر است:
- حافظه: حداقل 4 گیگابایت رم (بالای 8 گیگابایت، پیشنهادی)
- فضای ذخیرهسازی: حداقل 30 الی 40 گیگابایت فضای آزاد
آمادهسازی سیستم
برای بیلد فایرفاکس، نیاز به نصب پایتون نسخه 3.8 یا بالاتر دارید. اگرچه پایتون 2 دیگر برای بیلد فایرفاکس ضروری نیست، اما همچنان برای اجرای برخی تستها مورد نیاز است. علاوه بر این، احتمالاً به فایلهای توسعه پایتون نیز برای نصب برخی بستههای pip نیاز خواهید داشت. برای نصب آن در توزیعهای مبتنی بر دبیان میتوان از دستور زیر استفاده کرد:
$ sudo apt update && sudo apt install curl python3 python3-pipدریافت سورسکد
حالا که سیستم شما آماده است، میتوانیم سورسکد را دانلود کرده و اجازه دهیم فایرفاکس بهصورت خودکار وابستگیهای موردنیازش را دانلود کند. دستور زیر حجم زیادی داده (شامل سالها تاریخچه توسعه فایرفاکس!) را دریافت میکند و سپس در یک فرآیند نصب تعاملی، شما را راهنمایی خواهد کرد:
$ curl -L https://hg.mozilla.org/mozilla-central/raw-file/default/python/mozboot/bin/bootstrap.py -O
# To use Git as your VCS
$ python3 bootstrap.py --vcs=git بیلد و اجرا
در این مرحله سیستم شما برای فرآیند بیلد، آماده شده است. با دستور زیر میتوانید فرآیند بیلد را آغاز کنید:
$ ./mach buildدر صورت موفقیتآمیز بودن فرآیند بیلد، پیغام زیر نمایش داده خواهد شد.
Your build was successful!
To take your build for a test drive, run: |mach run|
For more information on what to do now, see
https://firefox-source-docs.mozilla.org/setup/contributing_code.htmlاکنون میتوانید با دستور زیر فایرفاکس بیلد شده را اجرا کنید:
$ ./mach runجهت دریافت اطلاعات بیشتر در رابطه با گزینههای اجرا، میتوان از دستور زیر استفاده کرد.
$ ./mach help runمرور کد
بهطورکلی پروسه پژوهش و کشف آسیبپذیری، شامل مطالعه، پیمایش و در نهایت درک حجم زیادی از کد است. بدیهی است که هر پژوهشگر ترجیحات منحصربهفرد خود را در زمینه مطالعه سورسکد دارد. با این حال، فناوریهای مفیدی در مواجهه با درختهای کد (Source trees) بسیار بزرگ (مانند مرورگرهای وب) وجود دارد، که باید آنها را در روندکاری خود ادغام کنند.
سرورهای زبانی (Language servers)، برنامههایی هستند که سورسکد را تحلیل کرده و یک دیتابیس قابلپرسش (Query-able) حاوی متادیتای زبانی پروژه ایجاد کنند. این ابزارها امکاناتی مانند، دنبال کردن سیمبلها، یافتن ارجاعات متقابل (Cross references)، تکمیل خودکار کد، دنبال کردن وراثت کلاسها و موارد دیگر را فراهم میکنند. معمولاً یک سرور زبانی را اجرا کرده، و از طریق یک پلاگین ادیتور به آن متصل خواهید شد. در صورتی که ترجیح میدهید بهجای IDEها، از ادیتورهایی مانند VIM یا EMACS کار کنید، دو پروژه زیر ارزش بررسی دارند.
- پروژه RTags
- پروژه ccls
وبسایت Searchfox به طور خاص برای پروژه موزیلا فایرفاکس ایجاد شده و امکان پیمایش سریع کد، پرش بین تعاریف و ارجاعات، و غیره را فراهم میکنند.
دیباگکردن
اگرچه مرورگرهای وب در نهایت فایلهای اجرایی هستند، دیباگ کردن آنها چالشهای منحصربهفردی دارد:
- اتصال به پروسه صحیح
- یافتن/دیباگکردن ترد صحیح
- درک ساختار کلی فضای آدرس
به طور کلی، دیباگرهای استاندارد با برخی افزونههای کمکی برای پژوهش بر روی مرورگرها استفاده میشوند: GDB در لینوکس، WinDbg در ویندوز، و LLDB در مک. در این مستندات، عمدتاً از GDB همراه با pwndbg استفاده خواهیم کرد. مستندات GDB احتمالاً بهطور پیشفرض بر روی سیستم به صورت Man Page در دسترس هستند. آموزش استفاده از GDB خارج از محدوده این سند است.
همانطور که پیشتر اشاره شد، فایرفاکس یک برنامه چندپروسهای (Multiprocess) است که شامل یک پروسه والد و چندین پروسه فرزند میباشد، که هر کدام بهصورت مجزا ایزوله شده و وظایف مختلفی دارند. جهت دیباگ پروسه والد میتوان از دستور زیر استفاده کرد:
$ ./mach run --debugger=gdbجهت دیباگ پروسههای فرزند، پس از یافتن پروسه صحیح، میتوان از دستور زیر استفاده کرد:
$ gdb --pid <pid>یافتن پروسه صحیح
راههای مختلفی برای یافتن PID پروسه موردنظر وجود دارد. برای مثال میتوان از Process Manager فایرفاکس استفاده کرد (ترکیب کلیدهای Shift+Esc یا مراجعه به صفحه about:process). راه دیگر استفاده از دستور زیر در ترمینال است.
$ ps ... | grep firefox گاهی اوقات نیاز است به یک پروسه فرزند در لحظه راهاندازی آن متصل شوید، تا مشکلاتی که در همان ابتدای اجرای پروسه رخ میدهند را بررسی کنید. با تنظیم متغیر محیطی MOZ_DEBUG_CHILD_PROCESS، اطلاعاتی مربوط به هر پروسه جدید چاپ میشود. همچنین پروسه با توجه به زمان تعیینشده توسط این متغیر (مثلا هر 10 ثانیه) توقف میکند تا فرصت اتصال دیباگر فراهم شود. یک نمونه خروجی در قسمت پایین قابل مشاهده است.
$ MOZ_DEBUG_CHILD_PROCESS=10 ./mach run
...
CHILDCHILDCHILDCHILD (process type tab)
debug me @ 3992
...نمونه 2: اجرای برنامه با تنظیم متغیر محیطی MOZ_DEBUG_CHILD_PROCESS
مقدمهای بر Document Object Model (DOM)
DOM یک ساختار درختی (سلسله مراتبی) از همه عناصر HTML موجود در یک صفحه وب است. در واقع این روش، دسترسی به تمام عناصر صفحات وب و امکان ایجاد تغییرات در آنها را فراهم میکند.
<!DOCTYPE html>
<html>
<head>
<title>My Text</title>
</head>
<body>
<h1>My Header</h1>
<p>My Paragraph</p>
</body>
</html>نمونه 3: محتوای یک نمونه سند HTML
با توجه به نمونه 3، تصویر پایین نشان دهنده ساختار DOM مربوط به محتوای HTML است.
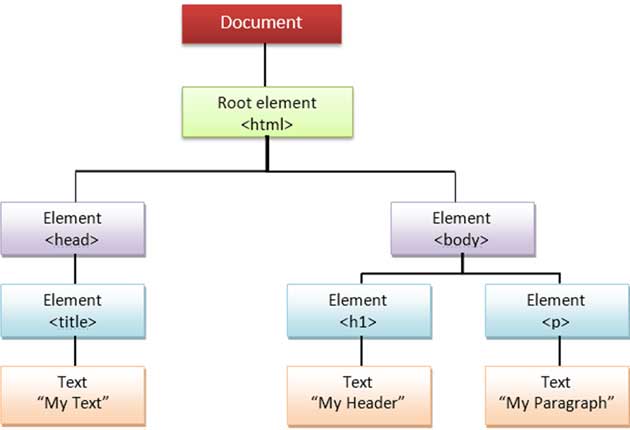
پیادهسازیهای DOM
در این بخش، نگاهی مختصر به چگونگی پیادهسازی DOM در مرورگرهای مختلف خواهیم داشت. در حال حاضر تمرکز ما بر روی کلیات است و خواهیم دید که مشخصات DOM در موتور مرورگرها، چگونه مستقیماً به کد C++ نگاشت میشوند.
موتور Blink
در نمونه پایین، نمایی کلی از نحوهی پیادهسازی کلاسهای اصلی DOM توسط موتور Blink (کرومیوم) ارائه شده است:
class CORE_EXPORT EventTarget : public ScriptWrappable { ... }
// A Node is a base class for all objects in the DOM tree.
// The spec governing this interface can be found here:
// https://dom.spec.whatwg.org/#interface-node
class CORE_EXPORT Node : public EventTarget { ... }
// HTMLElement class defined for Chromium
class CORE_EXPORT ContainerNode : public Node { ... }
class CORE_EXPORT Element : public ContainerNode { ... }
class CORE_EXPORT HTMLElement : public Element { ... }
// All the HTML tags are subclasses of HTMLElement
// Root document class for Chromium
class CORE_EXPORT Document : public ContainerNode, ... { ... }
// The Text class defined for Chromium
class CORE_EXPORT CharacterData : public Node { ... }
class CORE_EXPORT Text : public CharacterData { ... }نمونه 4 : پیادهسازی کلاسهای اصلی DOM توسط Blink در زبان C++
موتور WebCore
در نمونه پایین، نمایی کلی از نحوهی پیادهسازی کلاسهای اصلی DOM توسط موتور WebCore (WebKit) ارائه شده است:
class EventTarget : public ScriptWrappable { ... }
// Top level Node classes
class Node : public EventTarget { ... }
// HTMLElement class defined for WebKit
class ContainerNode : public Node { ... }
class Element : public ContainerNode, public CanMakeWeakPtr<Element> { .. }
class StyledElement : public Element { ... }
class HTMLElement : public StyledElement { ... }
// All the HTML tags are subclasses of HTMLElement
// Root document class in WebKit
class Document : public ContainerNode ... { ... }
// The Text class defined for WebKit
class CharacterData : public Node { ... }
class Text : public CharacterData { ... }
نمونه 5: پیادهسازی کلاسهای اصلی DOM توسط WebCore در زبان C++
موتور Gecko
در نمونه پایین، نمایی کلی از نحوهی پیادهسازی کلاسهای اصلی DOM توسط موتور Gecko (فایرفاکس) ارائه شده است:
class EventTarget : public nsISupports, public nsWrapperCache { ... };
// File: dom/base/nsINode.h
// The core DOM Node interface; defines child/parent navigation, nodeType, etc.
class nsINode { ... };
// File: dom/base/FragmentOrElement.h
// Container node for Element and DocumentFragment (implements nsINode + nsIContent).
class FragmentOrElement : public nsINode, public nsIContent { ... };
// File: dom/base/Element.h
// Base class for all element nodes (provides attribute handling, styling hooks, etc.).
class Element : public FragmentOrElement { ... };
// File: dom/html/HTMLElement.h
// HTML-specific element base (inherits from nsGenericHTMLElement).
class HTMLElement : public nsGenericHTMLElement { ... };
// File: dom/base/Document.h
// The root of the DOM tree; also implements document-level methods and lifecycle.
class Document : public FragmentOrElement, /* ...other interfaces... */{ ... };
// File: dom/base/CharacterData.h
// Base for all character-data nodes: Comment, Text, CDATASection, etc.
class CharacterData : public nsINode { ... };
// File: dom/base/CharacterData.cpp
// The Text class, representing text nodes in the DOM.
class Text : public CharacterData { ... };نمونه 6: پیادهسازی کلاسهای اصلی DOM توسط Gecko در زبان C++
عناصر HTML
در ساختار درختی DOM، عناصر HTML قابلیت گره(Node)های معمولی را گسترش میدهند. این عناصر از نظر مفهومی، معادل تگهای HTML هستند و نقش نوعی کانتینر را برای سایر محتوا ایفا میکنند. در سلسلهمراتب درختی، آنها گرههای والد تمام محتوایی هستند که بین یک جفت تگ HTML قرار گرفته است.
عناصر HTML مانند سایر گرهها میتوانند هدف رویدادها (Events) قرار بگیرند، میتوانند دارای ویژگی (Attribute) باشند و همچنین میتوان آنها را نامگذاری کرد (تا از طریق آن نام به آنها ارجاع داده شود). موارد زیر از ویژگیهایی هستند که تمامی عناصر HTML میتوانند داشته باشند:
- id: شناسه یکتا برای عنصر (در هر سند باید تنها یک عنصر با این شناسه وجود داشته باشد)
- name: نام عنصر
- class: تعیین تنظیمات نمایشی (استایل)
- Data Attributes: ویژگیهای سفارشی که با پیشوند data- آغاز میشوند (برای مثال data-user-id)
- سایر ویژگیها (به عنوان مثال، src برای تصاویر و href برای لینکها)
DOM API
DOM با استفاده از IDLها، یک API در اختیار JavaScript قرار میدهد تا با استفاده از برنامهنویسی امکان تعامل با سند فراهم شود.
// Select current elements
> let h = document.getElementById("header"); h
<h1 id="header">Example HTML</h1>
> h.firstChild
"Example HTML"
// Modify current elements
> document.body.remove(h)
// Create new elements
> let a = document.createElement('a');
> a.setAttribute('href','http://example.com')
// Append elements to the DOM
> document.body.appendChild(a)
<a href="http://example.com"></a>نمونه 7: تعامل با سند HTML با استفاده از JavaScript
کنسول توسعهدهنده (Developer Console)
با فشردن کلید F12، یا راستکلیک و گزینه Inspect، کنسول توسعهدهنده باز میشود. در اینجا ابزارهای متعددی برای بررسی درخت DOM، دیباگ JavaScript، مشاهده شبکه و منابع فراهم است. بیشتر قابلیتها مخصوص توسعهدهندگان وب است، با این حال ابزارهای مفیدی برای اهداف ما نیز وجود دارد.
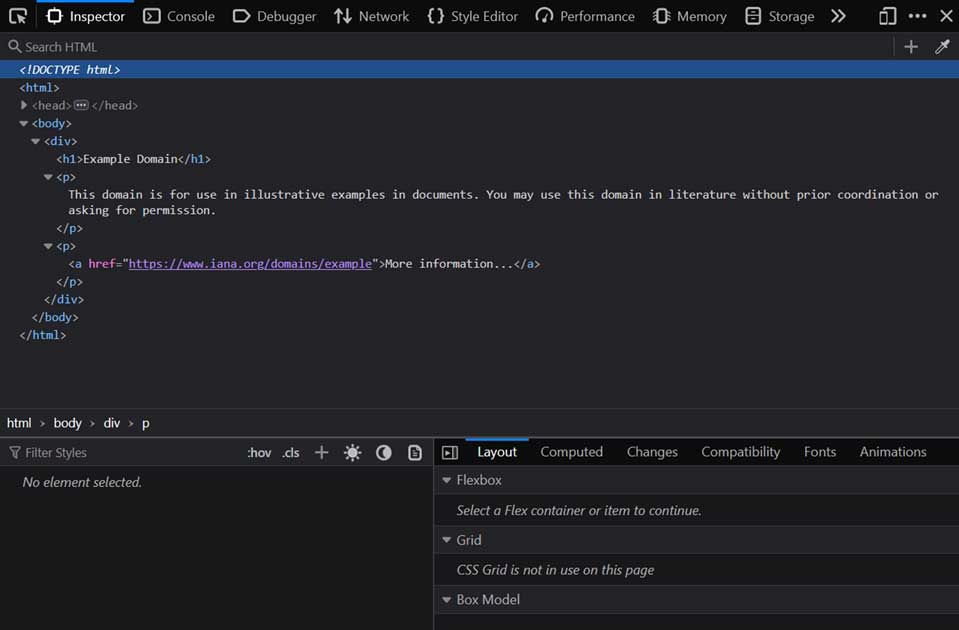
مدیریت حافظه DOM
همانطور که انتظار میرود، DOM به سرعت میتواند به ساختار دادهای بسیار پیچیده تبدیل شود. DOM از انواع مختلفی گره تشکیل شده است که دارای عمرهای متفاوت و رفتارهای پویا هستند. علاوه بر این، جاوا اسکریپت میتواند در هر زمان تغییرات گستردهای ایجاد کند. تمام اینها باعث میشود ارتباط میان گرهها بسیار پیچیده شود و این پیچیدگی مدیریت حافظه زیرین را دشوار خواهد کرد.
اگر صرفا با HTML ساده و خوشفرم سروکار داشتیم، ممکن بود بتوانیم روابط میان گرهها را با چیزی شبیه به تصویر پایین نمایش دهیم:
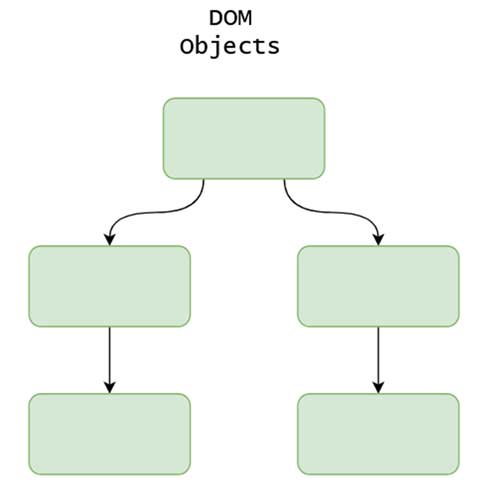
در چنین روابط سادهای، حتی با استفاده از الگوریتمهای نسبتا ابتدایی پیمایش درخت (Tree-traversal)، امکان مدیریت ارتباطات وجود دارد. اما در واقعیت، به دلیل بزرگی DOM بههمراه پیچیدگی جاوا اسکریپت، معمولا با چیزی شبیه به تصویر پایین روبهرو خواهیم بود:
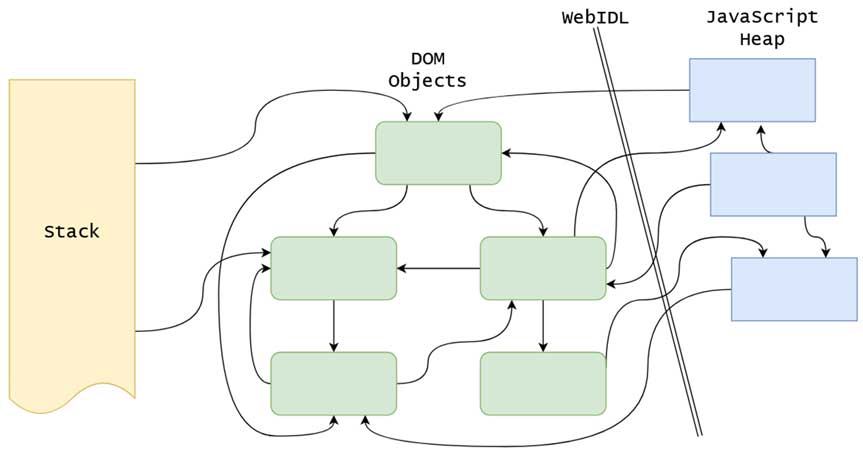
تصویر بالا نشان دهنده نوع روابطی است که مرورگرها در وب مدرن با آن سروکار دارند. در این وضعیت بهجای ساختار درختی تمیز، با ترکیبی از موارد زیر مواجهایم:
- گرههای والد
- گرههای فرزند
- گرههای همسطح
- ارجاعات جاوا اسکریپت
- ارجاعات پشته
- سایر ارجاعات
شایان ذکر است که تمام این روابط معمولا پویا هستند. پیادهسازی ضعیف مدیریت حافظه برای DOM، پیامد هایی همچون نشت حافظه و آسیبپذیریهای Use-After-Free (UAF) را به همراه دارد.
رویدادهای DOM
بهطور کلی رویدادها نشان میدهند که اتفاقی رخ داده است. رویدادها به آبجکتهایی ارسال میشوند که رابط EventTarget را پیادهسازی کردهاند. این آبجکتها سپس میتوانند به آن رویداد خاص واکنش نشان دهند. از انواع رایج اقداماتی که باعث ایجاد یک رویداد میشوند، میتوان به موارد زیر اشاره کرد:
- کلیک کردن روی یک عنصر با ماوس
- فشردن یک کلید
- تغییر وضعیت شبکه (آنلاین / آفلاین)
- اقدامات نمایشی در صفحه (اسکرول کردن، تغییر اندازه، تمامصفحه کردن، و غیره)
آبجکتهای EventTarget میتوانند با ثبت کردن شنوندههای رویداد (Event Listeners) از طریق جاوا اسکریپت، رویدادها را مشاهده کرده و به آنها واکنش نشان دهند. در سطح کد، ثبت و شنود رویدادها چیزی شبیه به نمونه زیر است:
someElement.addEventListener('click', (mouseEvent) => {
console.log("someElement received a 'Click' Event!");
if (mouseEvent.altKey) {
console.log("Looks like the ALT key was pressed too!");
doSomethingInteresting();
}
});نمونه 8: کد جاوا اسکریپت جهت شنود رویدادها
با توجه به نمونه 8، این کالبک (Callback) تا زمانی که مرورگر یک رویداد “کلیک” تولید نکند، اجرا نخواهد شد. ویژگی جالب دیگری که البته کمتر مورد استفاده قرار میگیرد، توانایی ارسال (Dispatch) رویدادها در سطح کد است:
someElement.addEventListener('click', (mouseEvent) => {
console.log("someElement received a 'Click' Event!");
if (mouseEvent.altKey) {
console.log("Looks like the ALT key was pressed too!");
doSomethingInteresting();
}
});
// Let's trigger the ALT+MouseClick functionality !!
someElement.dispatchEvent(new MouseEvent('click', {'altKey':true});نمونه 9 : کد جاوا اسکریپت جهت شنود و تولید رویداد
این کار به عنوان رویدادهای مصنوعی (Synthetic) شناخته میشوند، چرا که بهصورت برنامهنویسیشده تولید شدهاند، نه در نتیجه یک اقدام مستقیم از سوی کاربر، که بهطور معمول رویدادها را تریگر میکند.
رویدادها در زمینه تهاجمی
از دلایل اهمیت رویدادهای DOM در زمینه تهاجمی میتوان به موارد زیر اشاره کرد:
- Event Handlerها تقریبا در هر زمانی میتوانند اجرا شوند.
- ارسال رویدادها میتواند باعث شود موتور مجدد به جاوا اسکریپت بازگردد.
- یکی از نقاط رایج آسیبپذیر در سالهای گذشته بودهاند.
در حقیقت رویدادهای DOM میتوانند زنجیرهای از رفتارهای پیچیده را تقریبا در هر زمانی، میان حداقل دو زیرسیستم پیچیده و مستعد خطای مرورگر (جاوا اسکریپت و DOM)، راهاندازی کنند. این پیچیدگی معمولا منجر به بروز خطا میشود، بنابراین جای تعجب نیست که مدیریت چنین رویدادهایی میتواند دشوار و آسیبپذیر باشد.
مقدمهای بر معماری موتور JavaScript
موتور جاوا اسکریپت بخشی از مرورگر است که وظیفه پردازش و اجرای کد جاوا اسکریپت را بر عهده دارد. در این بخش، قصد داریم مفاهیم مشترکی که موتورهای جاوا اسکریپت باید پیادهسازی کنند را تعریف کرده، و نقاط چالشی، که موجب اتخاذ طراحیهای منحصر به فرد در موتورها میشود را برجسته کنیم. در این بخش انتظار میرود خواننده با مفاهیم پایه زبان جاوا اسکریپت آشنا باشد.
مقادیر JS
بهمحض شروع پیادهسازی یک موتور JS، یک مسئله معماری بنیادین پدیدار میشود. این موتورها با C++ نوشته شدهاند، زبانی با نوعدادههای ایستا و سختگیر، در حالی که جاوا اسکریپت آبجکتها و نوعدادههای بسیار پویا دارد. یک راه ساده این است که یک کلاس C++ با دو فیلد type و value تعریف کنیم:
class JSValue {
uint64_t type;
Value* value;
}
// Pointer to object somewhere
JSValue* obj;جاوا اسکریپت میتواند آزادانه type را تغییر دهد، و C++ مقدار value را بسته به زمینه مورد استفاده، تفسیر میکند. اما این روش ساده میتواند به سرعت باعث هدررفت حافظه شود. برای مثال برای نمایش یک عدد 32-بیتی، حداقل 32 بایت حافظه نیاز است:
- uint64_t: 8 بایت
- Value*: 8 بایت
- value : 8 بایت (حداقل)
- JSValue* : 8 بایت
اعداد JS
با توجه به مشکل عملکرد حافظه که در بالا اشاره شد، در ادامه راههایی را برای نمایش اعداد 32 بیتی (حداکثر سایز اعداد JS) بررسی میکنیم. بهعنوان اولین تلاش، میتوانیم value را درونخطی (Inline) کنیم. میدانیم این ساختار حاوی یک عدد خواهد بود، پس نیازی به دسترسی از طریق اشارهگر نیست:
class JSNumber {
uint64_t type;
uint64_t value;
}
JSNumber* obj;این کار در نهایت 24 بایت هزینه دارد، زیرا یک دسترسی اشارهگر را حذف کردهایم. با این حال، حتی میتوان بهتر از این هم عمل کرد. از آنجا که اعداد صحیح (Integers) جاوا اسکریپت تنها 32 بیت طول دارند، پس این امکان وجود دارد که از فضای اضافی درون یک فیلد عدد صحیح، برای ذخیره اطلاعات type استفاده کنیم.
class JSNumber {
uint64_t type_and_value;
}
JSNumber* obj;اکنون مصرف حافظه به 16 بایت کاهش یافته و اگر از اشارهگرها نیز صرفنظر کنیم، تنها 8 بایت خواهد بود. اما این کار یک مشکل دیگر ایجاد میکند. به کد زیر توجه کنید:
class JSNumber {
uint64_t type_and_value;
}
JSNumber* obj;
JSObject* obj2;در نمایش native، هر دوی JSNumber و JSObject* بهصورت اعداد 64-بیتی به نظر میرسند. مسئلهای که بهوجود میآید این است که موتورهای جاوا اسکریپت چگونه تفاوت بین این دو را تشخیص میدهند. شایان ذکر است که اگر در این تشخیص اشتباهی رخ دهد، منجر به type-confusion خواهد شد (یعنی عدد را بهاشتباه بهعنوان اشارهگر یا بالعکس در نظر بگیرند) و بهاحتمال زیاد قابل اکسپلویت خواهد بود.
آبجکتهای JS
برخلاف نوعهای اولیه (مانند Value و Number)، آبجکتهای JS نیاز به نگهداری اطلاعات بیشتری از سمت ما دارند:
- نوع آبجکت
- نگهداری بهصورت Key-Value با سایز دلخواه (properties)
- Prototype
- طول (برای آرایهها)
- اشارهگر به بافر حافظه (برای TypedArrays)
- موارد دیگر
سادهترین روش این است که کلاس JSValue خود را گسترش دهیم تا تمام ویژگیهای مورد نیاز را شامل شود:
class JSObject {
uint64_t type;
std::unordered_map<JSValue, JSValue> properties;
JSValue prototype;
... // Objects can add more fields
}همانطور که احتمالا متوجه شده اید، این کلاس نیز مانند نمونه اولیه JSNumber با برخی مشکلات هدررفت روبرو است:
- استفاده از Hash Map به منظور کش کردن رویکرد خوبی نیست و برای کلیدهایی با تعداد کم، پرهزینه است.
- Prototype و کلیدهای Property برای آبجکتهای مشابه تکراری میشوند.
در همان ابتدا امکان بهینهسازی برخی موارد وجود دارد:
- ذخیره Properties بهصورت آرایه
- اشتراکگذاری اطلاعات نوع
class Type {
uint64_t type;
JSValue prototype;
Name* property_names; // Indexes into property_array
// other shared metadata
}
class JSObject {
Type* type_information;
JSValue* property_array;
... // Objects can add more fields
}به این صورت، هر آبجکت اطلاعات Type یکسانی را به اشتراک میگذارد، بنابراین لازم نیست که هر کدام یک کپی از آن را همراه داشته باشند. علاوه بر این، از آنجا که اکثر آبجکتها دارای تعداد نسبتا کمی Property هستند، میتوان با ذخیرهسازی Propertyها بهصورت آرایه، هم در زمان و هم در فضا صرفهجویی کرد.
همانطور که گفته شد، میتوانیم برای رفع برخی مشکلات مربوط به استفاده از Hash Map، Propertyها را در یک آرایه ذخیره کنیم:
class JSObject {
Type* type_information;
JSValue* property_array;
... // Objects can add more fields
}ممکن است این سوال پیش آید که وقتی یک آبجکت JS تعداد زیادی Property نیاز دارد، چه اتفاقی میافتد. در واقع، هر زمان که از نظر عملکرد منطقی باشد، بهسادگی به استفاده از Hash Map سوئیچ میکنیم. از آنجا که برای تعداد زیادی از Propertyها، حالت خاص تعریف شده است، خوب است که برای تعداد پایینی از Propertyها نیز حالت خاص در نظر گرفته شود:
class JSObject {
Type* type_information;
JSValue* property_array;
JSValue[] inline_properties;
... // Objects can add more fields
}به این صورت، کد میتواند Propertyها را به آرایه inline_properties اضافه کرده و از یکبار ارجاع اشارهگر صرفنظر کند. این کار بهویژه در سناریوهایی که تعداد زیادی آبجکت کوچک وجود دارد مفید است.
عناصر
عناصر در واقع Propertyهایی هستند که بهجای کلید، با اعداد ایندکس میشوند:
let b = {};
b['a'] = 0x41424344; // This is a named property
b[0] = 0x41424344; // This is an element
let c = [1, 2, 3, 4]; // Arrays store elementsسادهترین راه برای پیادهسازی این مفهوم، در نظر گرفتن عناصر مانند Propertyها است. البته در این صورت با مشکل دسترسی کند مواجه میشویم، چون دسترسی به عنصر در این ساختار بهصورت O(n) خواهد بود. همچنین ممکن است فاصلههای بزرگ بین ایندکسها مشکلساز شود:
let a = [];
a[0] = 1;
a[100000] = 2;اختصاص واقعی این مقدار حافظه، بسیار پرهزینه خواهد بود. از این رو، موتورهای جاوا اسکریپت بهطور پویا تصمیم میگیرند که بسته به نحوه استفاده از آرایه، از آرایه سنتی یا Hash Map (آرایه پراکنده) استفاده کنند.
let a = []; // Empty element array
a[0] = 1; // Element array length 1
a[100000] = 2; // Switch to hashmapنوع آبجکت مشترک (Shared object type)
همانطور که پیشتر اشاره شد، اشتراکگذاری اطلاعات نوع (Type) میان آبجکتها راهی مؤثر برای صرفهجویی در فضا و افزایش کارایی است. این کار با تعریف یک ساختار اختصاصی برای توصیف نوع آبجکتها انجام میشود. سپس هرگاه یک آبجکت JS با آن نوع داشته باشیم، تنها به آن ساختار اشاره میکنیم.
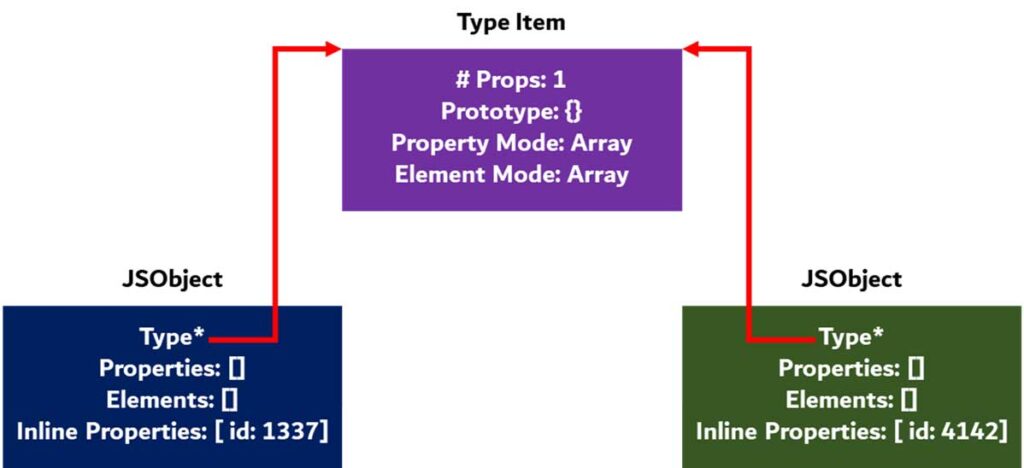
ممکن است صحبت درباره “نوع” در این زمینه عجیب به نظر برسد، زیرا از دید برنامهنویس، جاوا اسکریپت به اصطلاح یک زبان weekly typed است، اما در لایههای پایین، موتور همچنان پیگیر این است که هر آبجکت از چه نوعی میباشد. حال ممکن است این سوال پیش بیاید که در صورت ایجاد یک آبجکت جدید، موتور چگونه نوع مناسب را به آن اختصاص میدهد.
// We start with an empty object Type (lets call it type_0)
let obj = {};
// Create new Type for changed object (lets call it type_1)
obj.a = 1;
// Again we start with an empty object Type (type_0)
let obj2 = {};
// What do we do?
obj2.a = 2;این مسئله با استفاده از مفهوم انتقال نوع (Type Transition) حل میشود. ایده اصلی این است که تغییرات بین نوعها را بهصورت یک ساختار درختی ذخیره کنیم:
- هنگام ساخت یک Type جدید، تغییرات انجامشده را بهعنوان یک یال (Edge) ذخیره میکنیم.
- هنگام جستجو برای Type موجود، بین یالها میگردیم.
let obj1 = {};
obj1.a = 1;
obj1.b = 'hello';
let obj2 = {};
obj2.a = 2;
obj2.c = 1337;تصویر پایین نشاندهنده ترسیم درختی این اطلاعات است:
به این ترتیب، اگر تغییر مشابه قبلا رخ داده باشد، موتور میتواند آن مسیر را در درخت دنبال کند و از ایجاد مجدد یک ساختار Type جدید، جلوگیری نماید.